| 가상 메모리, Page fault handling
[정리]
1. 주제
- Page fault는 왜 발생하는 것이며, page fault 발생시 kernel은 어떻게 동작 하는가
2. 전체 내용 요약
1) 이론 필기 내용 요약
2) page fault tracing 실습
3) page fault handler 과정 확인
[1) 이론 필기 내용 요약]
OS에선 physical memory를 할당 하는 것이 아닌, virtual memory를 할당 함
page fault는 VA <-> PA 매핑이 되어 있지 않기 떄문에 발생하는 것
Segmentation fault 또한 page fault의 일종
Virtual address를 사용시 장점
1) ABI (Application Binary Interface)
- OS, CPU, 컴파일러 등이 함께 약속된 규약 (SYSCALL, clling convension, VA, ELF ..)
- ABI를 적용함으로써 binary만 제공되어도 바로 사용이 가능한 것이다.
2) 메모리 절약
3) 보안
4) 메모리 확장 (swap disk 활용)
- file system format과는 전혀 관계 없음
$ ps -eo pdi,comm,vsz,rss | head -2
현재 동작중인 task에 대해 pid, command, vsz (virtual memory size), rss (resident set size)에 대해 확인
vsz는 virtual memory size를 나타내므로, 실제 task가 .bss, .data, .text 등 모든 section을 memory에 loading할시에 필요한 메모리 크기를 나타냄
[2) page fault tracing 실습]

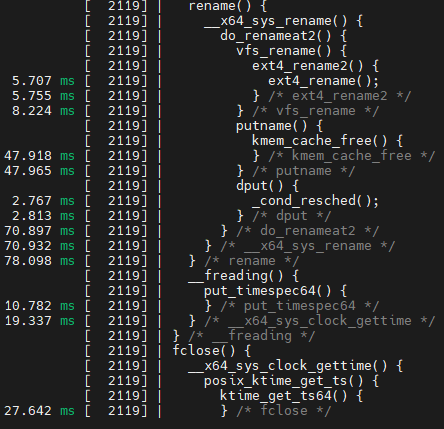
kernel영역에서 발생하는 page fault에 대해 tracing
# cd /sys/kernel/debug/tracing/
# echo 1 > events/exceptions/page_fault_kernel/enable
# cat trace_pipe(밑의 그림에서는 page_fault_kernel로 동작해 결과를 보여주지만,, 아래의 내용들은 kernel / user 유사한 부분이 많음)

address : page fault가 발생한 가상 주소
ip : page faule가 발생 했을 시점의 instruction 주소
error code :
$ vim ${linux}/arch/x86/include/asm/traps.h
위에서 발생한 error code=0x2의 의미는
error code : 0x2 = no page found + write + kernel mode access
커널 모드로 write를 수행하는데 page가 존재하지 않아 page fault가 발생함
이번에는 page fault가 발생한 부분에 대해 stacktrace를 사용해 call stack을 확인
기존 trace point 위치에서 실행
# echo 1 > options/stacktrace
# cat trace_pipe
copy_to_user 수행시 kernel mode에서 user 영역에 접근해 data를 write했을시 user 영역 주소가 존재하지 않아 page fault가 발생한 것임
보통 kernel 주소에 대해 page fault가 발생하는 경우는 거의 없음
[3) page fault handler 과정 확인]
$ vim ${linux}/arch/x86/entry/entry_64.S
page fault 발생시 page_fault가 호출되며, do_page_fault가 다시 호출되어 처리가 됨
이때, has_error_code, read_cr2는 밑의 do_page_fault함수의 argument (error_code = has_error_code, address = read_cr2)가 됨
cr2는 page fault를 일으킨 가상주소를 저장 함
$ vim ${linux}/arch/x86/mm/fault.c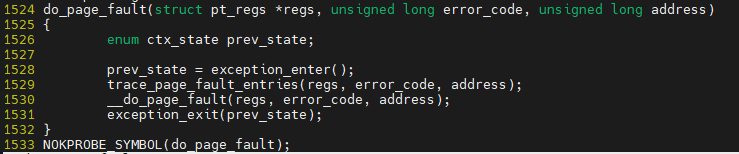
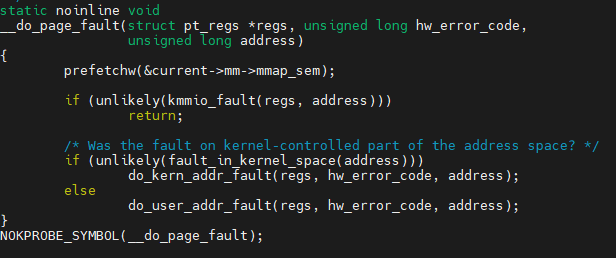
page_fault -> do_page_fault -> __do_page_fault -> do_user_addr_fault의 순서로 동작
(참조: 수업 중 do_kern_addr_fault이 아닌 do_user_addr_fault에 대해서만 진행 됨)

task가 접근한 page fault 주소를 알고 있으며, 해당 address에 대해 task_struct -> mm_struct -> vma 영역 (text, stack, heap,...) 중 어느 영역에서 page fault가 발생 했는지 확인

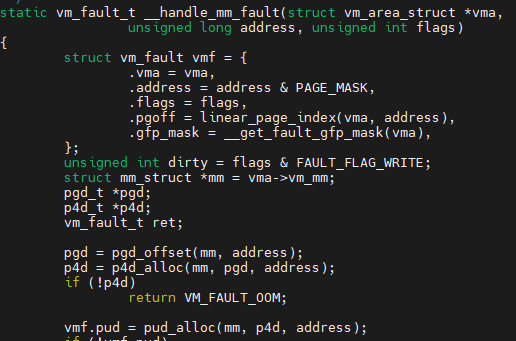
handle_mm_fault -> .. -> __handle_mm_fault에서 VA-PA 변환테이블을 수정 함
조금 더 자세한 내용들은 뒤에 연속적으로 나옴
__handle_mm_fault -> handle_pte_fault -> do_anonymous_page에서 PA를 위한 page를 할당 받음
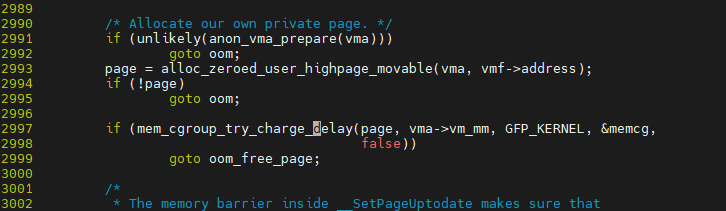
page 할당 이후 실제 page table entry 요소에 대해 업데이트 수행
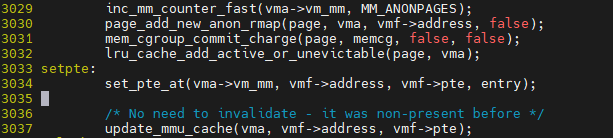
위의 과정에 대해 다시 정리하자면
do_user_addr_fault() : arch/x86/mm/fault.c
-> handle_mm_fault() : mm/memory.c
-> __handle_mm_fault() : mm/memory.c
-> handle_pte_fault() : mm/memory.c
-> ptep_set_access_flags() : arch/x86/mm/pgtable.c
-> set_pte() “페이지 테이블 한요소(pte) 수정”
'Linux Kernel' 카테고리의 다른 글
| [운영체제] [리눅스 커널 5.0 동작과정 이해와 tracing 실습] 2일차 - 가상메모리, Page fault handling (2/2) (1) | 2021.10.07 |
|---|---|
| [운영체제] [리눅스 커널 5.0 동작과정 이해와 tracing 실습] 2일차 - 수업 중 필기 (0) | 2021.10.06 |
| [운영체제] [리눅스 커널 5.0 동작과정 이해와 tracing 실습] 1일차 - uftrace를 통해서 user + lib + kernel 호출과정 추적하기 (0) | 2021.10.05 |
| [운영체제] Coredump, dmesg (0) | 2021.03.19 |
| [커널] nvme device driver 분석 자료구조 (0) | 2021.02.02 |