
total = used + free + buff/cache
used -> anonymous page : programming으로 사용되는 것, heap, stack등 같은
buff/cache -> disk상의 내용이 메모리상에 유지될떄, page cache를 말함
available -> free + buff/cache, process가 처음에 최초로 실행이 된다면, 최대치로 사용할 수 있는 메모리의 양

buffers : inode block과 같은 파일 정보
cached : data block의 파일 내용
pagecache -> buffers/cached 모두 나타냄


task의 최대 vsz크기는 unlimited로 설정되어 있음 -> 32bit OS이라면 2^32, 64bit OS이라면 2^64
-------------------------------------------------------------------------------------------------------------------------
Multi-level page table에 대해 이론 설명
참조 :
http://jake.dothome.co.kr/pt64/
https://www.kernel.org/doc/gorman/html/understand/understand006.html
pgd (page global directory)
pud (upper)
pmd (middle)
pagetable
pte (page table entry)

현재 사용중인 kernel에서 page table level을 확인 하는 방법
실습은 각자 하는 것으로, compile 시간이 너무 오래 걸림
-------------------------------------------------------------------------------------------------------------------------
mmap에 대한 실습 진행
#include <stdio.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <unistd.h>
#include <fcntl.h>
#define READ_SIZE 16
int main(int argc, char **argv)
{
int fd, flag = PROT_WRITE | PROT_READ;
struct stat sb;
char *addr;
if ((fd = open(argv[1], O_RDWR|O_CREAT)) < 0) {
printf("File Open Error\n");
return -1;
}
if (fstat(fd, &sb) < 0) {
printf("fstat error\n");
return -1;
}
addr = mmap(NULL, READ_SIZE, flag, MAP_SHARED, fd, 0);
if (addr == MAP_FAILED)
printf("mmap error\n");
printf("%s\n", addr);
memset(addr, 0x00, READ_SIZE);
munmap(addr, READ_SIZE);
close(fd);
}https://github.com/hackndev/tools/blob/master/devmem2
와 비교해서 차이점 확인 해 보기
실행 방법
$ hexdump -x mmap_test.txt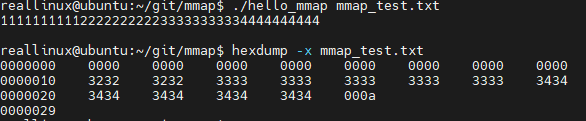
-------------------------------------------------------------------------------------------------------------------------
disk cahce 비우기


mmap에 대한 trace 추적
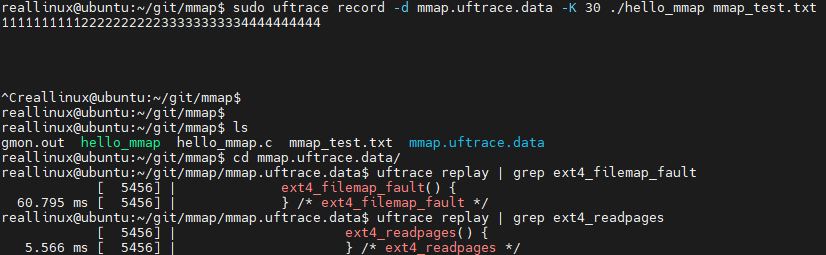

page fault 발생해 처리하는 부분에 대해 확인할 수 있음
밑에 이어 지는 것을 보면, block layer에 request 생성 후 요청하는 부분까지 이어져있음
mmap에서 받은 addr에 대해 memset을 통해 data write 수행시 puts()가 불리게 되며,
기존에 이미 echo 3 을 통해 disk cache flush가 되었으므로, va-pa 연결이 끊겨져있음,
따라서 puts() 수행시 page fault가 발생하고 지난번에 배운것 처럼 page fault handler 로직이 호출됨
anonymous page 정리 : https://blog.daum.net/thehalfmoon/2
mmap 수행시 fd를 안주고 NULL을 했다면, anonymous page가 되는 것임
우리가 만든 mmap_test.txt 파일이 ext4 fs위에서 생성되었기 때문에 __do_fault()내에서 vma->vm_ops->fault()가 ext4_filemap_fault()와 연결되는 것임. 만약 다른 fs이라면 vma에 다른 함수가 연결될 것임
이번에는 read로 직접 데이터를 읽는 것에 대해 tracing 진행
$ vim read.c
$ cat read.c
#include <stdio.h>
#include <stdlib.h>
#define SIZE 16
void main()
{
FILE *fp = fopen("mmap_test.txt","r");
char buf[BUFSIZ];
if (fp) {
fread(buf, SIZE, 1, fp);
printf("%s", buf);
fclose(fp);
}
}


mmap을 했을 경우 puts()를 통해 진행되고 read의 경우 syscall에 의해서 동작하게 됨 서로 다른 call path를 가지게 됨
mmap vs. read 성능 비교
작은 size 크기를 1번 읽고 그만 한다면 성능상 큰 차이는 없겠지만, 많은 양의 데이터를 연속적으로 읽는다고 했을시 caching으로 인해 mmap이 조금 더 성능이 좋음
-------------------------------------------------------------------------------------------------------------------------
유저+커널 가상 주소 범위 알아 보기

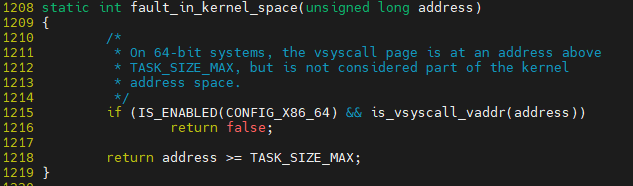
__do_page_fault 에서 address가 kernel영역인지 user 영역인지 확인하게 됨
그 부분을 확인시 TASK_SIZE_MAX와 비교해 판단 함
memory 영역 참조 자료: https://wogh8732.tistory.com/397
user와 kernel은 어떻게 메모리 영역을 나눠 사용 하는지에 대해 파악이 필요함
여기에서 ZONE이라는 용어가 나오며 해당 자료들에 대해 조사 필요
-------------------------------------------------------------------------------------------------------------------------
커널에서 메모리 할당 하는 방법
alloc_pages
kmem_cache_alloc
kmalloc -> 메모리에 선 할당되어 있는 영역에서 할당을 해주기 떄문에 연속적으로 할당 할 수 있다.
vmalloc -> 후매핑용 영역에서 할당하기 때문에 물리적으로 연속됨을 보장 할 수 없는 것임


struct page는 kernel에서 page를 관리하는 주체를 말하는 것이며, page내 vitrual 변수가 실제 메모리에 할당된 page를 가르키게 됨


alloc_pages 수행시 orders를 통해 몇 page를 할당 헀는지 확인 가능함. order =0 1page 할당
-------------------------------------------------------------------------------------------------------------------------
buddy system 정보 확인과 rmqueue 함수 추적

buddy info 보기 쉬운 python 스크립트
#!/usr/bin/env python
# vim: tabstop=4 expandtab shiftwidth=4 softtabstop=4 textwidth=79 autoindent
"""
Python source code
Last modified: 15 Feb 2014 - 13:38
Last author: lmwangi at gmail com
Displays the available memory fragments
by querying /proc/buddyinfo
Example:
# python buddyinfo.py
"""
import optparse
import os
import re
from collections import defaultdict
import logging
class Logger:
def __init__(self, log_level):
self.log_level = log_level
def get_formatter(self):
return logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
def get_handler(self):
return logging.StreamHandler()
def get_logger(self):
"""Returns a Logger instance for the specified module_name"""
logger = logging.getLogger('main')
logger.setLevel(self.log_level)
log_handler = self.get_handler()
log_handler.setFormatter(self.get_formatter())
logger.addHandler(log_handler)
return logger
class BuddyInfo(object):
"""BuddyInfo DAO"""
def __init__(self, logger):
super(BuddyInfo, self).__init__()
self.log = logger
self.buddyinfo = self.load_buddyinfo()
def parse_line(self, line):
line = line.strip()
#self.log.debug("Parsing line: %s" % line)
parsed_line = re.match("Node\s+(?P<numa_node>\d+).*zone\s+(?P<zone>\w+)\s+(?P<nr_free>.*)", line).groupdict()
#self.log.debug("Parsed line: %s" % parsed_line)
return parsed_line
def read_buddyinfo(self):
buddyhash = defaultdict(list)
buddyinfo = open("/proc/buddyinfo").readlines()
for line in map(self.parse_line, buddyinfo):
numa_node = int(line["numa_node"])
zone = line["zone"]
free_fragments = map(int, line["nr_free"].split())
max_order = len(free_fragments)
fragment_sizes = self.get_order_sizes(max_order)
usage_in_bytes = [block[0] * block[1] for block in zip(free_fragments, fragment_sizes)]
buddyhash[numa_node].append({
"zone": zone,
"nr_free": free_fragments,
"sz_fragment": fragment_sizes,
"usage": usage_in_bytes })
return buddyhash
def load_buddyinfo(self):
buddyhash = self.read_buddyinfo()
#self.log.info(buddyhash)
return buddyhash
def page_size(self):
return os.sysconf("SC_PAGE_SIZE")
def get_order_sizes(self, max_order):
return [self.page_size() * 2**order for order in range(0, max_order)]
def __str__(self):
ret_string = ""
width = 20
for node in self.buddyinfo:
ret_string += "Node: %s\n" % node
for zoneinfo in self.buddyinfo.get(node):
ret_string += " Zone: %s\n" % zoneinfo.get("zone")
ret_string += " Free KiB in zone: %.2f\n" % (sum(zoneinfo.get("usage")) / (1024.0))
ret_string += '\t{0:{align}{width}} {1:{align}{width}} {2:{align}{width}}\n'.format(
"Fragment size", "Free fragments", "Total available KiB",
width=width,
align="<")
for idx in range(len(zoneinfo.get("sz_fragment"))):
ret_string += '\t{order:{align}{width}} {nr:{align}{width}} {usage:{align}{width}}\n'.format(
width=width,
align="<",
order = zoneinfo.get("sz_fragment")[idx],
nr = zoneinfo.get("nr_free")[idx],
usage = zoneinfo.get("usage")[idx] / 1024.0)
return ret_string
def main():
"""Main function. Called when this file is a shell script"""
usage = "usage: %prog [options]"
parser = optparse.OptionParser(usage)
parser.add_option("-s", "--size", dest="size", choices=["B","K","M"],
action="store", type="choice", help="Return results in bytes, kib, mib")
(options, args) = parser.parse_args()
logger = Logger(logging.DEBUG).get_logger()
#logger.info("Starting....")
#logger.info("Parsed options: %s" % options)
#print logger
buddy = BuddyInfo(logger)
print buddy
if __name__ == '__main__':
main()

기본적으로 처음 시작시 order=10 -> 4MB 크기 단위로만 존재하며, 추후 page 요청에 의해 분할되며 크기에 맞게 메모리를 할당하게 됨
여기서 처음 조각을 지속적으로 분할해 사용한다고 해서 rmqueue라는 명칭을 사용함
ex) 2^10 -> 2^9 * 2 형태로 분할
__free_one_page에서 최종적으로 버디시슽메 기반 메모리 해제 작업 수행
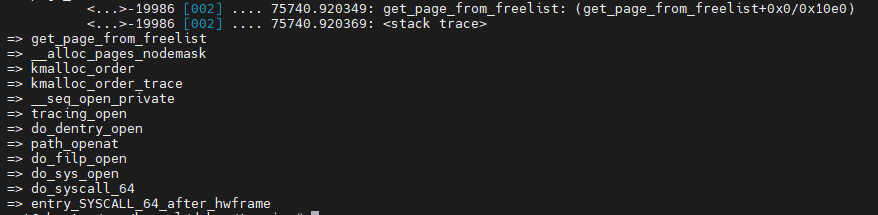
메모리 해지 free 사례 추적

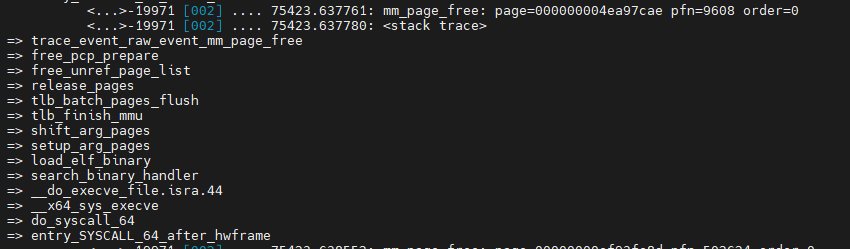

mm free list를 가지고 있음. kprobe에 등록해 확인 해보자
-------------------------------------------------------------------------------------------------------------------------
slab 할당자
객체 창고?


현재 OS에서 사용하고 있는 방법
slab vs. slub vs. slob 차이점?
크게 slab이 동작하는 것이고 거기 안에서 세부 동작이 달라 지는 것임



vim ${linux}/include/linux/slab_def.h
vim ${linux}/inlcude/linux/slub_def.h
vim ${linux}/inlcude/linux/mm_types.h 내 struct page 확인시 freelist가 존재함
slub은 여러개의 page에 걸쳐 관리되는 자료구조들에 대해 freelist를 동해 연결되어 있음


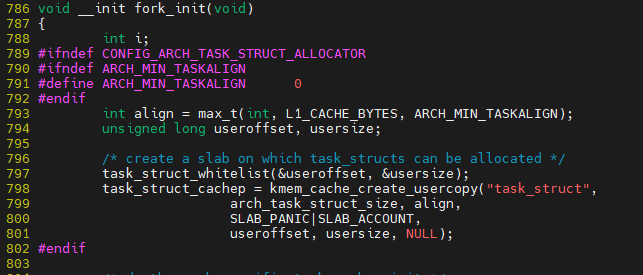
kmem_cache_create_usercopy()를 통해 kmem_cache_create 호출되면서 task_struct를 위한 page가 할당됨

do_fork에서 task 생성시 do_fork -> .... -> kmem_cache_alloc_node를 통해 할당

할당 된 부분에 대해 해제 하는 부분 kmem_cache_free()
-------------------------------------------------------------------------------------------------------------------------
vmalloc 과정 추적
echo 'p:vmalloc vmalloc' > probe_events
echo 1 > events/kprobes/vmalloc/enable
echo 1 > options/stacktrace


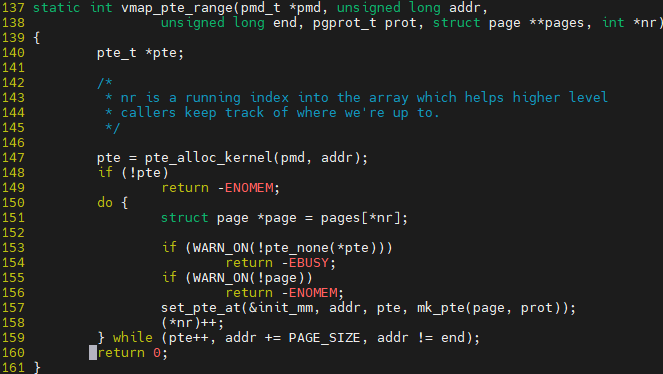
루프를 돌며 필요한 page 개수만큼 할당 받게 된다. 후 매핑이므로 VA-PA 연결을 해줘야 하며 그 부분은 map_vm_area에서 진행하게 된다
마스터 페이지 테이블에 같이 적어 놓는다. 그리고 다른 task가 해당 vm위치에 접근시 마스터 페이지 테이블의 내용을 복사해 사용하게 된다.
저기에서 init_mm은 마스터 페이지 테이블을 나타낸다.
현재 페이지 테이블에 해당 내용이 적혀 있지 않다. MMU에 대해서도 init_mm에 접근하지 못한다.
따라서, fault가 발생할 것이다.
vmalloc에 대한 page fault handler 처리
vim arch/x86/mm/fault.c::vmalloc_fault

fault 발생한 주소가 후매핑용 vmalloc 영역이 맞는지 확인
*pdg, *pdg_k 두개가 존재하는건, 현재 페이지 테이블과, 마스터 페이지 테이블 두개를 사용하기 위함
348번 라인이 해당 의미를 타나냄. read_cr3_pa -> 현재 페이지 테이블 내용 읽기
pgd_k -> 마스터 페이지 테이블임
핵심은 355번 라인에서 마스터페이지 테이블의 내용을 현재 페이지 테이블의 내용에 복사 해옴

오프셋 계산도 결국 마스터 페이지 테이블에서 가지고 오는 것임
마스터 커널 페이지 테이블이 존재 하는 이유
pmd, pud, ... 모든 process들이 공유함
마스터 커널 페이지 테이블 pgd에 해당 되는 것은 전역 변수로 가지고 이씅ㅁ
이것을 따로 있는 이유는 프로세스가 생성되기도 하고 죽기도 하고 여러개가 있을텐데 그때마다
페이지테이블이 생성이 되는데 그 페이지 테이블에 대해 모두 커널영역에 ㄷ해ㅐ 각각 세팅하기엔 오버헤드이다?
-------------------------------------------------------------------------------------------------------------------------
페이지 회수과정 추적
LRU 같은 스킴에 의해서 현재 페이지의 개수가 High/Low/Min 기준으로 판단되어 page-out/swap-out 된다.
이것을 kswapd 프로세스가 진행하며, 개수 기준에 따라 동작을 한다. kswapd가 종료되진 않는다.


swap 유발시키는 스크립트
#!/usr/bin/python2
import numpy
result = [numpy.random.bytes(1024*1024*2) for x in xrange(1024)]
print len(result)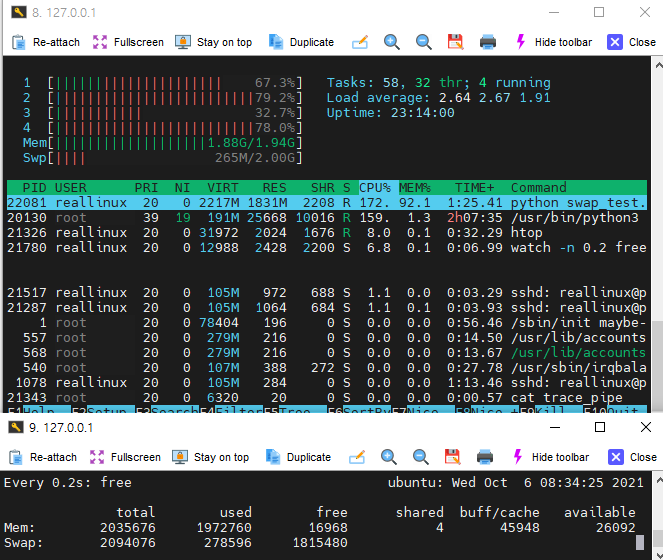

python script가 page를 많이 소비하고 있으며, 그때마다 page 할당을 위해 swap한다. 이때 swapd0에 의해 swap이 발생되는 trace를 확인할 수 있었고 free 수행시 swap의 used 개수가 증가함을 확인 가능했다.
swap 영역까지 최대로 다 사용하면 더이상 page를 할당 할 수 없는 상황이 되며, 그때 process를 강제로 OOM에 의해 종료된다.

kswapd는 무한루프 진행..
balance_pgdat 너무 오랫동안 사용하지 않음 page들에 대해 page out 수행
kswapd_shrink_node -> shrink_node -> ... -> shrink_list

LRU 형태로 inactive list 멤버에 대해 정리
kswapd
-> balance_pgdat
-> kswapd_shrink_node
-> shrink_node
-> shrink_node_memcg
-> shrink_list
-> shrink_inactive_list
-> shrink_page_list
-> pageout
__alloc_pages
-> __alloc_pages_nodemask
-> __alloc_pages_slowpath
-> __alloc_pages_direct_reclaim
-> __perform_reclaim
-> try_to_free_pages
-> do_try_to_free_pages
-> shrink_zones
-> shrink_node
-> shrink_node_memcg
-> shrink_list
-> shrink_inactive_list
-> shrink_page_list
-> pageout