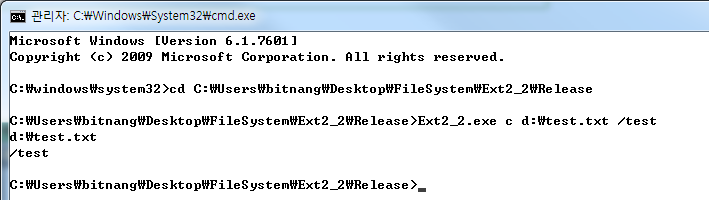
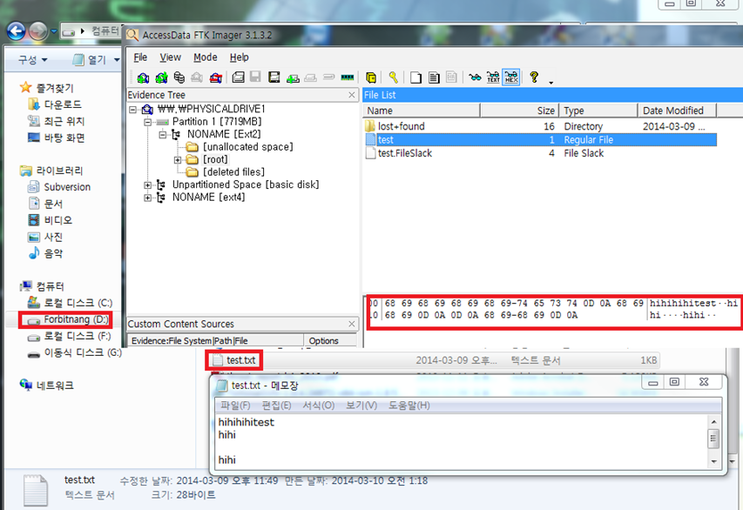
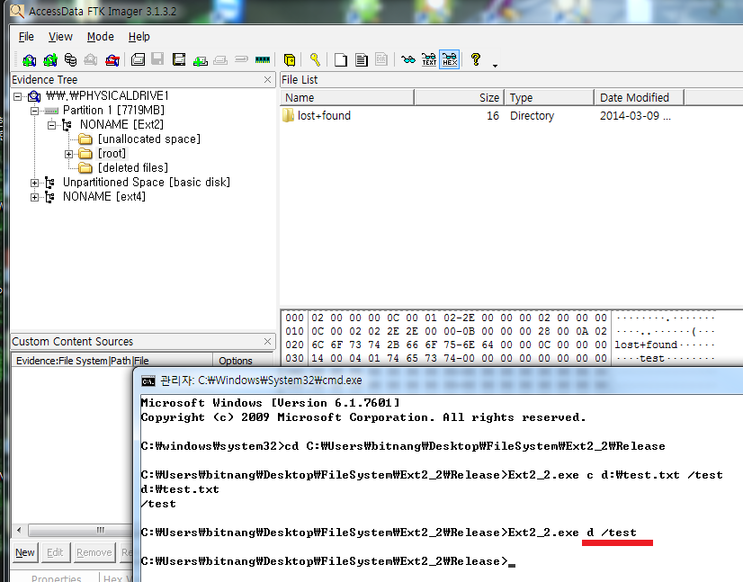
지난 몇주동안 Linux kernel의 block I/O layer가 어떻게 동작하는지 명확하게 이해하기 위해 연구하고 분석했다. Modena and Regigio Emilia 대학교의 한 동료 학생이 내가 blog 게시물을 쓸것이라고 생각했다. OPW mentor가 topic을 승인했고 block 게시물을 몇개의 part로 나누어서 지루 한번에 지루해 지지 않고 더 편안하게 읽을 수 있도록 하는것을 제안했다. Block I/O layer에 구현된 메커니즘의 기본 개념과 아이디어를 설명하는 Part one 이다 : 매우 high-level 이고 간결하다. 다음 Parts(구현 세부사항에 대해 좀더 자세하게 설명할것이다.)는 block layer가 노출하는 다양한 API들이 그러한 메커니즘을 사용하는 방법과, 잘하면 각 왜 그것들이 각 APIs들에 대해 유용한지(or 그렇지 않은지) 간략하게 설명할 것이다. 꽤 어려운 목표인것 같다(적어도 나와 같은 초급자에게). 만약 비판할게 있으면, 코멘트를 남겨라.
block I/O layer는 block devices에서 수행되는 input/output operations을 관리하는 kernel subsystem이다. 그러한 operations을 관리하기 위한 specific kernel component에 대한 필요성은, 예를들어, character devices에 대해 block device의 추가적인 복잡성에 의해 발생한다.
character device(우리가 사용하고 있는 keyboard)에 대해 생각했을때, 오직 한방향만을 따라 움직이는 cursor가 있는 stream에 대해 생각한다. 다른말로, steream에 보관된 정보는 오직 하나의 순서로만 읽을수 있으며 일반적으로 특정 위치 or 특정 문자를 발견할때까지 읽는다. (EOF, the end-of-file character). block device는 다르다. 한 번 이상의 seeks후에, 어느 순서나 어느 위치에서든 data를 읽을 수 있다. I/O 자체를 처리하는것 보다 성능을 보장하기 위해서 block device에서 읽는 동안에 특별한 주의가 필요하다.
사실, block I/O device들은 storage device로 주로 사용되고, 가능한 그것들의 잠재력을 최대한 활용하는 것이 중요하다. Rovert Love가 그의 유명한 책에서 언급한 것처럼, block layer의 개발은 Linux kernel의 2.5 개발 cycle의 주요 목적이 된 중요한 목표였다.
그것을 black box로 보았을때, block layer는 Linux kernel의 2개의 다른 관련된 subsystem과 상호 작용을 하는것을 발견했다. mapping layer and 실제 I/O가 발생하는 block device의 device driver. Mapping layer가 무엇이고 block layer아 어떻게 상호작용하는지 이해 하기위해 block I/O request가 실제로 어떻게 도달하는지 간략하게 윤곽을 설명해야 한다.
Figure 1: The block I/O hierarchy of the Linux kernel
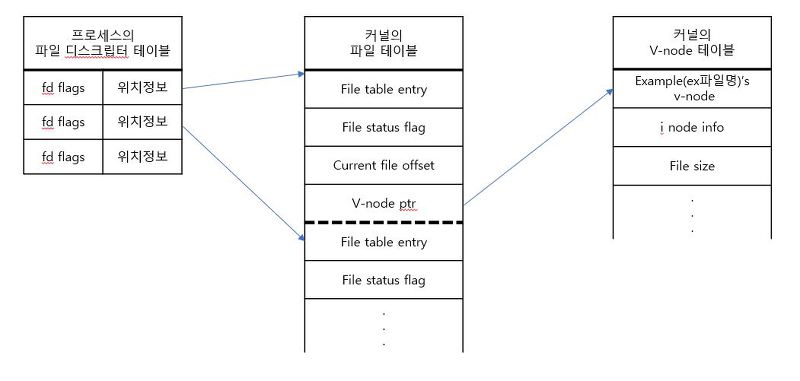
process는 일정 수의 bytes의 read() or write() operation을 사용하여 disk에 접근한다. sys_read() and sys_write() system call은, library 대신 호출 되고, 먼저 Virtual File System을 활성화는, 2개의 다른 측면을 처리한다.
파일을 opening, closing or linking할때, 상대 or 절대 경로에서 시작해서 data를 가지는 the disk and file system을 찾는다. 이미 열려진 file을 읽거나 쓸때, data가 이미 memory에 mapped되어 있는지 확인한다(즉, kernel’s page cache에 존재하는지) 만약 그렇지 않다면, 어떻게 data가 disk로 부터 읽는 방법을 결정한다.
VFS가 data가 이미 memory에 mapped 되지 있지 않다는것을 알게 되면, physically하게 data를 찾는 kernel subsystem을 활성화 한다. mapping layer는 처음에는 data에 해당하는 file system block의 크기를 찾은 다음 전송될 disk blocks의 수로 data의 크기를 계산한다.
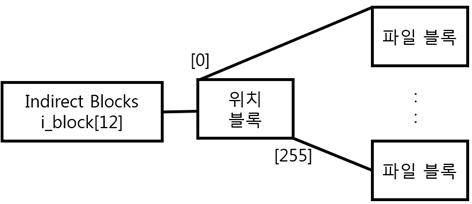
이 단계에서, kernel은 또한 data를 보관하는 block numbers를 찾는다. file이 물리적으로 연속하지 않은 block에 보관 될 수 있기 때문에, file system은 logical blocks 와 physical blocks사이에서의 mapping을 추적한다. 그래서 mapping layer는 file descriptor에 접근하고 the logical-to-physical mapping을 함게 처리하는 mapping 함수를 호출해야 하므로 결국에는, file을 보관하는 실제 disk blocks의 위치를(disk의 or disk’s file system의 paritition으로 부터) 얻는다.
memory에 mapped된 block의 position이 이용 가능해지면, kernel은 disk device로 전달할 I/O requests를 만드는것을 시작한다.
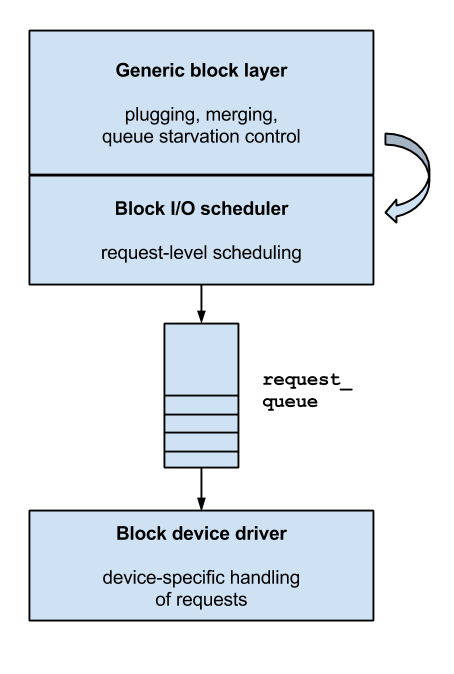
block I/O layer는 block I/O 구조(bio)의 리스트를 생성하는데, 각 구조는 disk에 제출되는 I/O 동작을 나타낸다. 그러한 구조는 계층의 상위레벨에게 block deivce의 특정 기능을 숨기고 장치의 추상적인 개념을 제공한다. small I/O 동작의 가장 단순한 경우, single bio가 생성되지만 보다 복잡한 경우에(larget-sized I/Os, vector I/O) block layer는 한번에 더 많은 I/O 동작을 시작할 수 있다. 결과적으로, block layer는 I/O operation을 특정 sector에 대한 request로 변환하여 disk controller에게 전송한다. 보통 각 request는 하나 이상의 bio들을 포함한다. 이것은 per-structure processing overhead를 줄이는데 도움이 된다.
이 requests들은 각각 request structure에 의해 표현된다. device driver에 대한 그들의 발송(dispatch)은 block layer의 I/O scheduling sub-component에서 구현된 service policies에 의해 제어 될 수있다.
Figure 2: Interaction between bio and request data structures(from R. Love's "Linux Kernel Development", 3rd Edition)
마침내, block layer는 실제 data 전송을 처리하는 device driver에게 I/O request를 보낸다.
device driver는 일반적으로 사용가능한 request의 list를 제공받거나 or 일부 shared data 구조체에 request를 넣기 위한 callback을 제공한다. device driver는 interrupt가 disk에서 발생되자마자 or request service가 계층 구조의 상위레벨에서 요청되는 즉시 interface-specific command를 보낸다.
block layer 와 device driver사이의 상호 작용은 사용되는 block layer API에 크게 의존한다. 그리고 훨씬 많은 세부 사항을 다음 post에서 논의할것이다.
I/O handling techniques
질문이 여기에서 자연스럽게 생긴다. request가 block layer에 의해 block device driver에게 단순히 forwarded되나? 실제로 no. 만약 실제로 그렇다면 block I/O layer의 존재는 무의미하다. 대신, block layer는 I/O 개수를 제어하는 기술을 구현한다. 그것들 중 몇몇은 매우 간단하고 몇몇은 매우복잡하며 일반적인 목적은 성능 향상이다. I/O scheduling과 같은 구현된 기술중 일부는 block layer에 의해 제공되는 API들의 일부분이므로 여기서 설명하지 않는다. 그러나 일부 API는 사용된 API와 관련 없이 이익을 제공하므로 모든 사용 가능한 interface에 공통이다.
Merge and coalesce I/O operations
block I/O layer가 block I/O operation에서 수행하는 첫번째 동작은 이미 삽입된 구조체에 그것을 merge하는것이다. 이것은 block layer’s 내부 데이터 구조체에서 일부 근접한 requests를 찾는것으로 달성된다. 만약 적어도 하나의 인접한 request가 발견되면, 새롭게 발행된 block I/O이 기존의것에 통합된다. 기존의 operation이 새로운것에 merge될때( 새로운 것이 기존의 것 앞에 섹터에 대해 발행된것 이기 때문에); merge는 front merge라 불린다. 그렇지 않으면, 새로운 operation이 기존것에 merge된다면(기존의 것 다음의 섹터에 대해 발생된것이기 때문이다), merge는 back merge라 불린다.
2개의 가장 흔한 경우는 후자이다. I/O 가 순차적인 방식으로 수행되는것이 가장 흔하게 발생하기 때문이다.
대신, 새로운 operation이 2개의 이미 존재하는 구조체 사이의 틈을 채울때(“fill a gap”), block layer는 3개의 동작을 병합한다(coalesce).
Figure 3: Merge and coalesce operations
Plugging
block I/O layer는 request 가 device driver에세 전달되는 rate를 조정하는 plugging이라는 메커니즘이 포함되어 있다. 만약 request 가 block layer가 load or stress로 간주 되지 않는 (pending requests의 수가 적은) block device에 queue 되면, driver에게 newly-issued operation의 dispatch는 지연된다(devices는 plugged된다고 불린다.) 이것은 block layer가 많은 수의 merges를 수행하도록 한다, 만약 더 많은 I/O가 밀접하게(시간과 공간상) 발행되면 block layer가 더 많은 수의 merge를 수행할 수 있다.
일정 시간이 지나거나 또는 device에 대해 outstanding I/O의 수가 고정된 threshold를 초과하면, device는 unplugged 되고, requests는 실제로 device driver에 dispatch된다.
디스크에서 I/O request를 처리하는 속도는 request의 크기에 영향을 받지만, 개수에도 영향을 받는다.
다시 말해서, 8KB를 한 번 읽는것보다 4KB를 두 번 읽는 것이 훨씬 느리다. 실제로 디스크가 platter에서 정보를 읽어내는 시간에 비해, 그 외 준비 하는 시간이 크기 때문이다.
디스크 상에서 연속적인 request를 두 개 처리하는 것보다 하나로 merge된 request를 처리하는 것이 빠르기 때문에
request queue를 막아서 dispatch을 멈춘 상태 (plugged)를 만들어서 최대한 request를 merge하고, dispatch를 멈추지 않는 상태 (unplugged)를 만들어서 dispatch를 하는 것이 block layer 성능 향상 기법인 'plugging' 이다.
(즉, dispatch 횟수를 줄이기 위해서 device의 request가 적은 상태일 때, 최대한 많은 수의 merge를 수행한 뒤에 dispatch 하는 것.)
처음에, plugging은 system-wide에서 수행되었다. 이 idea는 효율적이라고 증명되었지만 plugging이 per-device로 수행되면 효과적이지 않다. 이것은 점점 증가하는 SMP 머신에서 lock 경쟁을 완화하는데 도움이 될것이다.
2.6.39부터, plugging은 per-device로 옮겨졌다. Lock contention은 여전히 문제였다. 특히 많은 프로세스들이 동일한 block device에 많은 수의 작은 request를 발생하는 경우와 끊임없이 block I/O operation의 merge가 발생 할때마다 block layer’s per-device 자료 구조체에 접근하는 경우이다.(Hitting on) 3.0 부터 plugging은 per-process로 옮겨졌다. 이것은 block I/O operations이 많은 경우에 lockless 방식으로 merged and coalesced 되는것을 허용한다. 실제로 lock 경쟁에서 이 디자인의 선택의 영향의 범위는 사용되는 API에 의존한다.
2.6.34의 plugging 구현을 종합하자면 다음과 같다. * request queue가 비어있을 때 request가 들어오면 plug한다. * plug하고 3ms가 지나면 자동으로 unplug한다. * 3ms내에 request가 4개 이상 들어와도 unplug한다.
2.6.34의 구현에는 다소 문제가 있다.다음 request가 3ms안에 들어오지 않을 수도 있다는 것이다. Synchronous request하나만 보내놓고 응답을 기다리는 경우, 결국 3ms timer가 expire될 것이다. 그렇다면괜히 반응성만 3ms나빠지게 되는 것이다. 하지만 block layer에서는 다음 request가 언제 들어올지 정보가 전혀 없다. 따라서 어쩔 수 없이 기다리는 것이다.
앞서 Linux 2.6.34에서 plug구현의 문제점에 대해 살펴봤다. Linux 3.0에서는 plug의 구현을 수정하고,plug를 파일시스템 레벨에서 이용하게 함으로써 문제를 해결했다. 결국 request를 생성하는 것은 파일시스템인데, 파일시스템에서는 request가 산발적으로 생성되는 것이 아니라, 뭉텅이 지어서(clustered) 생성되기 때문이다. Linux 3.0에서는 plug를 사용하는 패턴은 다음과 같이 수정됐다.
* plug 상태를 request queue가 아니라 task(thread)에 체크한다.
* plugged 상태가 되면, 그때부터 발생하는 request를 쌓아두었다가 unplugged 상태가 되면, 한번에 request queue에 삽입한다.
즉, 정리하자면 2.6에서는 'request queue'에 request가 들어왔을 때, plugging을 했다. 3.0에서는 'request queue'에 request를 삽입하기 전, 프로세스(파일시스템)에서 plugging을 한다.
Request sorting
일부 유형의 block device는 가능한 순차적인 방식으로 request를 보낼때 큰 이익을 얻는다. 아마도 쉽게 추측할 수 있게지만, 가장 많이 이익을 얻는 경우는 data에 대한 접근 시간이 몇몇 mechanical(기계적인) 움직임에 의존하는 디바이스에서 이다. (rotational hard drivers). Sector에 접근할때 rotational disk는 sector가 head에 접근 될수 있도록 데이터가 보관된 disk plate를(rotational latency) 움직여야 하며 특정 track (disk head seek)에 head가 위치하여야 한다.
만약 requests가 랜덤하게 발행되면, sectors를 검색하기 위해 필요한 seeks의 수가 증가해서 순차적으로 발행된 동작과 관련하여 overhead가 증가한다.
block layer는 일반적으로 가능한 한 많은 request를 reorder해서 device driver and disk에게 순차적인 방식으로 제출한다. Plugging은 block layers는 request를 제출하기전에 내부적으로 re-order하게 해준다.
Figure 4: Internals of a hard disk (from learn44.com, because I can't draw for my life)
그러나 request sorting은 data transfer time이 오직 request의 사이즈에만 의존하는 SSD와 같은 몇몇 종류의 disk에서는 유용하지 않다. 몇몇 solid state disk들은 실제로 내부적으로 병렬로 처리해서 더 좋은 성능을 얻을 수 있기 때문에 더 많은 작은 requests를 갖는것에서 이익을 얻는다. 따라이 이 테크닉은 그것이 엄격하게 필요한 경우에만 사용되도록 I/O policies에게 남겨지며 중요하지 않거나 or 성능에 불필요한 영향을 주는 overhead를 야기하는 몇몇 경우에는 직접 skipped된다.
The request interface
나의 OPW mentor가 제시한 많은 지침과 제안을 따르면서, 나는 매우 작고 간단한 block I/O driver를 구현했다. 그 driver의 multi-queue 구현은 process가 발행된 CPU core에 대해 사용 가능한 정보로 단지 I/O request 구조를 채우기만한다. 이것은 내가 개발중인 multi-queue-capable prototype의 block I/O를 테스트 하는데 매우 유용하다는것을 증명하고 있다.
이번 임무를 통해 내가 Linux kernel의 block layer가 제공하는 다양한 APIs들을 깊이 있게 더 공부할 수 있는 기회를 주었다. 그리고 그것에 대해 블로그 기사 시리즈를 계속 쓸수 있는 기회를 주었다.
request interface는 block layer가 device driver에게 requests를 전달할 수 있게 하는 essential data 구조를 기반으로 한다 : requet_queue 구조체; 그러한 구조체는 2개의 주요 buffering 기능을 가진다. 그것은 request가 overheads를 줄이기 위해 pre-processed되는것을 허용하고(merging and sorting) submission rate를 제한하여 hardware buffer가 over-running하는것을 방지한다. request_queue 구조체는 device별로 할당되므로 device에는 전용 request_queue가 있으며 이것은 disk에 사용중인 device-specific block I/O driver에 의해서만 접근이 가능하다. 그러한 구조는 본질적으로 block I/O request의 container이다. 실제로 더 중요한 항목은 driver가 사용할 수 있게 된 requests의 link list이다(head는 queue_head 항목에 유지된다.)
그것은 또한 제출을 위해 처리되어야 하는 bio를 제출을 위해 사용되는 function의 포인터 집합을 유지하거나 device에 request를 보내는데 사용되는 함수에 대한 포인터의 집합을 유지하거나 device에게 제출을 위해 처리 할 request를 전달한다. request mode에서 block layer는 I/O scheduling도 허용한다. 그래서 request_queue 구조체는 elevator_queue 구조체를 가리키고 elevator_queue 구조체는 elevator hooks에 대한 포인터를 가진다.
마지막으로 request_queue 구조는 spin_lock(queue_block)에 의해 보호된다.
Figure 1 : The block layer's layout when in request mode
앞으로 나아가고 각각의 black boxes안에 무엇이 있는지 알고 싶다면, 좋은 출발점은 trace 이다. 그러나interrupt를 실행하고 우리가 직접적으로 trace를 얻는것을 허용하지 않는 전체 driver-specific and low-level-driver-specific 함수의 방해 없이 명확하게 어떻게 request를 trace할 수 있는가? 우리는 가장 명확하게 가능한 trace를 얻기 위해 몇몇 ftrace tricks를 활용할 수 있을것이다. 나는 개인적으로 후자를 좋아한다. 그것은 Linux kernel은 module로 load할때 구성 가능한 수의 fake block devices(module의 nr_devices options을 참조)를 만들고, 선택한 block layer API(queue_mode 옵션으로 제공)을 사용하여 module을 구성한다.
이 driver의 다른 멋진 feature는, 기본 설정일때, dispatches and completion을 포함한 모든것이 request 삽입의 context에서 발생하는 것이다.
PID로 간단하게 trace할수 있을 만큼 완벽하다.
나는 reuquest interface를 사용하여 4KB read request 제출한 trace를 수집했으며 업로드하자 마자 이용가능하게 할것이다.
그러나 첫번째 흥미로운 사실은 device의 초기화할때 발생하기 때문에 trace에 의해 보여지지 않는다. 새로운 device를 초기화 할때, driver가 loaded되는 동안에, 특정 device에 대해 block layer에서 사용할 interface를 선택한다.
인터페이스는 일반적으로 bulk_queue_make_request() helper 함수로 정의된 make_request_fn를 지정하는것으로 선택된다.
block layer가 request mode일때 사용되는 기본 make_request 함수는 blk_queue_bio()이다.
block layer에게 bio를 제출하는 함수를 알게 되었고 trace에서 그것을 쉽게 발견할 수 있었으며, submit_bio()에 호출 되는 generic_make_request()에 의해 호출된다.
후자의 function은(submit_bio()) block layer에 대한 일종의 entry point이며 device에게 처리,제출되는 block I/O unit를 제출하기 위해 block I/O stack의 상위 수준에서 사용된다.
submit_bio() -> generic_make_request()
그러나 위에 언급한 것들에서 가장 흥미로운 함수는 blk_queue_bio()이다. 그것은 Linux block layer’s request mode의 core routine를 구현한다. flowchart를 준비했지만 그것은 너무나 길어 질것이므로 다음의 paragraph에서 수행되는 핵심이 되는 부분만 간단히 설명한다. 여기서 일부분 생략한다. 독자들이 읽기에 지루한 것은 뺐다. 만약 전체 함수를 알고 싶다면, Linux kernel source tree의 block/blk-core.c의 1547부분에서 찾을 수 있다.
Generic block layer: the blk_queue_bio() function
어떤 lock을 획득하기 전에 수행되는 첫 번째 단계는, 새롭게 제출 된 block I/O unit를 tasks’s plug list에 있는 requests와 merge를 시도하는 것이다. request mode일때, plugging은 실제로 per-process로 수행된다
if (blk_attempt_plug_merge(q, bio, &request_count)) return;
blk_attempt_plug_merge() 함수는 bio 구조체를 현재 issuer’s(발행자의) plug list와 merge하려고 한다. 기본 merging paramters(blk_try_merge()의 실행으로 수집된)만을 체크하여 elevator와 어떤 상호작용을 피할수 있으므로 locking이 수행될 필요가 없다.
계속해서 block I/O unit은 per-device structure가 포함되므로 blk_queue_bio()함수는 결국 queue_lock을 획득해야 한다.
spin_lock_irq(q->queue_lock); el_ret = elv_merge(q, &req, bio); if (el_ret == ELEVATOR_BACK_MERGE) { if (bio_attempt_back_merge(q, req, bio)) { elv_bio_merged(q, req, bio); if (!attempt_back_merge(q, req)) elv_merged_request(q, req, el_ret); goto out_unlock; } } else if (el_ret == ELEVATOR_FRONT_MERGE) { if (bio_attempt_front_merge(q, req, bio)) { elv_bio_merged(q, req, bio); if (!attempt_front_merge(q, req)) elv_merged_request(q, req, el_ret); goto out_unlock; } }
elv_merge() 함수는 이미 evelator에 queued된 request와 bio 구조체를 merge하기 위한 시도와 관련된 모든 동작들을 처리한다.
이를 위해, block layer는 이 동작을 더 빠르게 수행할 수 있도록 몇몇 private 항목들을 유지한다.
a) 성공적으로 merge에 관여한 last request의 one-hit cache.
b) elevator에서 현재 dispatch를 기다리고 있는 private list of requests.
(a)가 가장 유용하다. 만약 merge가 one-hit cache와 성공할 경우,list를 통한 동작은 필요하지 않다.
아마도 (b) elevator에서 검색을 elevator 자체에 위임 할 경우 여러 multiple search level을 암시하는 다른 service queue에 분산될수 있어서 검색 속도가 빨라 질수 있다.
elv_merge()함수는 bio와 request가 merge될수 있는지 확인하기 위해 elevator hooks중 하나를(elevator_allow_merge_fn) 호출하는것과 관련된다. 그것은 bio와 request가 수행할 merge의 종류를 나타내는 값을 반환한다.
merge가 성공한 경우, device는 즉시 unlocked되고 함수는 반환한다.
req = get_request(q, rw_flags, bio, GFP_NOIO); if (unlikely(!req)) { bio_endio(bio, -ENODEV); /* @q is dead */ goto out_unlock; }
block layer는 각 device에 대해 이미 할당된 request 구조의 pool을 유지한다.
할당된 requests의 개수는 특별한 sysfs file인 /sys/block/<device>/queue/nr_requests를 읽어서 확인 할 수 있으며
device에 대한 In-flight requests의 개수는 /sys/block/<device>/inflight에서 확인 할 수 있다.
모든 bio의 merge가 실패한 경우, blk_queueu_bio()는 pool에서 free request를 얻기 위해 get_request()를 실행한다. 그것이 실패한 경우, 후자에 의해 호출되는 __get_request() 함수는 request starvation logic을 활성화 하여 모든 application에 대해 모든 I/O request가 blocking되게 한다(심지어 write request조차). 대신, 만약 free request 구조체가 정확하게 검색되면, __get_request()는 elevator_set_req_fn elevator hook를 호출하여 request의 elevator-private 항목을 초기화 한다.전자 함수가 반환될때 blk_queue_bio는 bio에 포함된 정보로 초기화 한다.
init_request_from_bio(req, bio);
새로운 request가 bio에 보관된 정보에서 정확하게 검색되고 초기화 된후에, issuing tasks’s plug list에 삽입되거나 elevator에 직접 제출되어야 한다. per-process-plugging logic이 실행된다.
새롭게 초기화된 request는 task가 현재 plugged 되었고, 등록된 list의 길이가 BLK_MAX_REQUEST_COUNT를 초과 하지 않거나 or task가 충분한 짧은 시간동안 plugge되어 있는 경우에만 task’s plug list에 삽입된다. 그렇지 않으면, 만약 task가 plugged되었다면 unplugged되고 plug list는 blk_flush_plug_list() 함수로 flush된다. 만약 task 가 unplugged되면, driver run-of-queue가 발생하고 새로운 request가 elevator_add_req_fn hook로 추가되어 추가적인 처리를 위해 직접 elevator에 전달된다.
The elevator and the device driver
Run-of-queue가 발생했을때, driver는 request queue를 살펴보고 requests가 있으면 queue에서 하나 이상의 requests를 빼낸다. Queue의 실행은 request 삽입의 결과 또는 device’s controller의 인터럽트에 따라서 발생할수 있다. Driver 초기화중에, request_fn 함수는 blk_init_queue() 함수로 설정되며 새로운 request_queue structure도 할당한다. Device가 request_queue로 부터 새로운 requests를 얻으려는 경우 run-of-queue는 driver’s request_fn hook를 실행한다. 일반적으로 후자는 유효한 request를 반환하지 않을때 까지 block layers의 blk_fetch_request() 함수를 실행한다. Loop안에서 driver는 적절하다고 판단되는 requests를 처리한다.
null block driver가 request_fn 함수의 초기화를 어떻게 처리하는지 알아보자. 완전한 null_add_dev()함수의 source code는 Linux kernel source tree의 drivers/block/null_blk.c에 있다.
blk_fetch_request() 함수는 blk_peek_request() 함수를 호출한다. request_queue에 새로운 request를 삽입하기 위해 차례로 elevator’s callbacks중 하나인 blk_peek_request() 함수를 사용한다. 각 dispatch에 삽입되는 requests의 수는 elevator에 구현된 scheduling policy의 구현에 의존한다.
The make request interface
지난주 동안, bottlenecks를 찾아 lock contention issues를 해결하기 위해 작업하고 있는 driver를 검토해야 하므로 virtual machine에서 동작하는 operating system의 profiling에 관해 공부를 하게 되었다. 나의 멘토가 perf 와 lockstat와 같은 몇몇 인기있는 profiling tool을 이해할것을 제안했다. 학사 논문 중에 이미 얼마간 perf에 익숙해 지는 기회를 있었지만 Virtualized OS의 performance에 대해 정확한 data를 수집하는것에 대해 좀더 많이 배우고 있다.
예를 들어, XEN은 performance-related data를 수집하기 위해 Intel’s Performance Monitoring Unit을 활용한다고 들었다.
profiling에 앞서 tests를 수행하는 동안에, 나는 greedy random readers and writers로 구성된 random workload로 CFQ and NOOP I/O schedulers의 성능을 비교하기 위해 null_blk block device driver를 사용할 기회가 있었다. (completion latecny가 없다.) 그러한 workload는 too-fast-to-be-real-device에서 Intel’s IOmeter를 emulate한다. CFQ I/O scheduler에 의한 처리량은 I/O를 발행하는 process의 수에 따라서 NOOP에 의해 달성된 처리량의 1/2이거나 심지어 더 낮다.
그러나 NOOP scheduler는 여전히 requests를 merge and sort를 한다. 이것들은 I/O operations이 랜덤한 방식으로 발행되는 workload와 sort를 정당화 하는 seek penalty가 없는 작업에서는 정말로 필요하지 않아 보인다. 그래서 Linux kernel’s block layer에는 이미 무엇인가가 있는데 그것은 NOOP scheduler에 있는 request API보다 조금 더 나은 성능을 보여줄 것이 있다.
make request interface (or bio-based interface)는 본질적으로 bio structure의 생성후에 block I/O unit의 모든 처리를 끊는 것이다. 그래서 kernel은 직접 storage device’s driver에게 bio를 직접 submit할 수 있다. 그러한 interface는 실제 underlying device에게 그것들을 제출하기전에 request의 pre-processing을 수행하는것이 필요한 모든 block device driver에게 유용한다. 심지어 그것의 목적이아니더라도, bio-based API는 block layer’s I/O request처리를 overhead로 보는 모든 device driver에게 또한 유용하다. 예를 들어, 매우 복잡한 internal request processing logic이 특징으로 하거나 or requests가 처리 될 필요가 없는 device driver or controller에게 유용하다.
그러한 interface의 drawbacks는 분명하다 : 그것을 이용하는 driver는 일반적으로 block layer의해 수행되는 모든 pre-processing을 잃을것이다.
Figure 1 : Block layer layout when using the make request interface
매우 간단하게 null_blk driver 코드에서, driver가 그러한 interface를 어떻게 사용하는지 알아보자. bio-based mode일때도, null_blk driver는 여전히 request_queue structure를 할당해야 한다. 그러나 핵심은, 기본적인 것과 관련하여 alternate make request 함수를 정의하는 것이다.
null_blk driver는 이것을 null_add_dev()함수에서 한다. 이 함수는 module를 초기화 할때 생성해야 하는 각 simulated device(가상 장치)에 대해 호출된다.
bulk의 null_queue_bio() 함수 자체를 살펴보자. 매우 간단하고 새로운 request structure를 할당할 필요조차 없다. 그러나 이후에 completions을 다루기 위해 command structure가 필요하다. 그것은 추가적인 작업없이 단지 block operations’s command 만을 다룬다.
static void null_queue_bio(struct request_queue *q, struct bio *bio)
{
struct nullb *nullb = q->queuedata;
struct nullb_queue *nq = nullb_to_queue(nullb);
struct nullb_cmd *cmd;
cmd = alloc_cmd(nq, 1);
cmd->bio = bio;
null_handle_cmd(cmd);
}
매우 단순한 경우, 마치 device controller에 의해 실행된것처럼 error notification없이 I/O command를 종료함으로써 completion이 처리된다. 이전에 본 null_handle_cmd() 함수의 context 내에서 직접 실행되는 end_cmd()함수에서 null_blk driver가 어떻게 수행하는지 볼 수 있다. block layer’s bio_endio()함수에 완료된 bio와 두번째 매개변수로 error code를 전달하여 함수를 호출한다.
case NULL_Q_BIO:
bio_endio(cmd->bio, 0);
break;
The multi-queue interface
몇주전에 null_blk device driver로 생성된 simulated device를 사용하여 prototype driver에 대한 몇가지 첫번째 tests를 수행했다. 그러한 테스트와 다음의 profiling은 frontend driver에 의해 유지 되는 internal lock의 경쟁에 의한 locking issues들을 강조했다. 좀더 자세하게 말하면, 그러한 lock은 block I/O driver의 fronted 와 backend parts사이에서 requests and responses를 교환하기 위해 사용되는 ring buffer를 처리하는데 도움이 된다. lock은 새로운 request의 삽입과 response의 추출로 부터 ring을 보호하다. 그래서 나의 멘토는 ring을 2개의 부분으로 나누는것을 제안햇다. 하나는 request를 위한것, 다른 하나는 response을 위한것으로 사용 되었다.
지난 일주일 반동안, 나는 그것에 대해 연구 했다. Interface를 이전 버전의 driver의 요구와 일치하게 만드는것에 어려움을 겪는 동안 나는 series를 결론 짓는 multi-queue block layer API에 대한 마지막 blog 기사를 작성했다.
다음 주에 performance에 관련된것으로 당신을 지루하게 할것이다.
또한, 이 post는 internship의 첫주 동안에 내가 만든 일부 문서의 보상이다. 그것은 나의 멘토의 reading이 도움이 되었기 때문에 그래서 아마도 평소보다 좀더 정확할 것이다.
request interface는 초당 수백개의 I/O operation을 처리할 있는 device용으로 설계 되었다. 최근 논문에서block layer 메인테이너인 Jenx Axboe는 수천만의 IOPS를 처리할수 있는 device에서 사용될때 설계상의 문제를 겪고 있다고 언급했다.(첫 번째 블로그 게시물 or Jens Axboe 논문 참조). 중요한 issues중 하나는 lock contention은 오직 multiple cores들이 동시에 block I/O requests들을 삽입하고 계속해서 singe queue_lock에서 spinning한다면, 매우 관련된 영향 끼친다.
그러한 상황은 lock이 interrupt를 발생시키는 high-end storage device에 의해 lock을 얻으려하고 드라이버가 여전히 같은 lock에서 spinning하고 있을때 악화될것이다.
multi-queue API는 block I/O controller가 여러 requests를 병렬로 처리할 수 있는 능력을 이용하는것으로 해결하므로 lock contention이 크게 감소한다. 사실, 그것의 일반적인 구성에서, request_queue를 lock하는 필요 없이 block I/O request 삽입할 수 있다. 어떻게 하는지 살펴보자.
blk-mq API는 2개의분리된 request queues : software staging queue 그리고 block device에 의해 제공되는 실제 hardware queue의 숫자와 매칭되는 수의 hardware dispatch queue를 사용하는 two-levels block layer design을 구현했다.software staging queues의 갯수는 hardware dispatch queues의 수보다 클수 있다. 이 경우, 2개 이상의 software의 큐가 같은 hardware context의 일부분 일것이다. 그리고 해당 hardware context에서 수행되는 dispatch는 모든 관련된 software queues에서 requests를 가져올것이다.
대신, software staging queue의 개수는 hardware queue의 수보다 적을수 있다. 이경우 sequencial mapping이 수행된다. 3번째 그리고 가장 간단한 경우는 software queue의 갯수가 hardware queue의 개수가 같다. direct 1:1 mapping이 수행된다.
Figure 1: Outline of the multi-queue block layer.
Main data structures
multi-queue block layer API에 의해 사용되는 첫번째 관련 data structure는 blk_mq_req structure이며 새로운 block devicefmf block layer에 등록 하는 동안 모든 중요한 정보들 포함한다.
이 data structure는 blk_mq_ops data 구조체애 대한 포인터를 포함하고 있으며 multi-queue block layer에서 device’s driver와 상호작용하는데 사용되느 specific routines의 track을 유지하기 위해 사용된다.
blk_mq_req 구조에는 또한 초기화될 hardware queue의 개수, queue의 dept(깊이?) 그리고 block layer에서 특정 driver와 관련된 data structures의 초기화 동안에 유용한 다른 정보들 유지한다.
다른 중요한 data structure는 blk_mq_hw_ctx structure이다. 그것은 requesut_queue와 연관된 hardware context를 나타낸다. software staging queue에 해당하는 structures는 per-CPU별로 할당되는 blk_mq_ctx structues이다.
이 contexts사이에서 mapping을 수행하는 함수는 drivers의 blk_mq_ops data structure의 map_queue 항목에 지정되며, 반면에 이 함수에 의해 구성된 mapping은 block device와 관련된 request_queue data structure의 mp_map으로 유지된다.
걱정하지 마시오. 그림 2를 보면 더 명확해 진다.
Figure 2: Data structures used in the multi-queue block layer.
multi-queue API를 사용하는 새로운 driver가 load되면, 새로운 bulk_mq_ops 구조가 만들어지고 초기화 되고 blk_mq_req의 관련 pointer에 주소를 설정한다 . 좀더 자세하게는, 필요한 operations들은 command를 처리하는 담당하는 함수인( low-level driver에게 그것을 전달하는것으로) queue_fn 과 그리고 hardware와 software context사이에서 mapping을 수행하는 map_queue이다. Queue initialization
다른 동작들은 반드시 필요하지는 않지만 I/O request의 완료나 context의 생성시에 특정한 동작을 수행하기 위해 구현될수 있다. 필요한 data에 경우, drive는 그것이 지원하는 submission queue의 갯수를 그들의 사이즈에 따라 초기화 해야만 한다. 예를 들어 driver에 의해 지원되는 command size및 block layer에 노출 되어여 하는 specific flags를 결정하기 위해 다른 data들이 필요하다.
새로운 device 가 초기화 될때, driver는 device를 처리하는 device driver에 따라 type이 다양한 새로운 new data 구조체를 준비한다. - driver-specific data structure-, 그러나 device’s gendisk struct 와 device와 관련된 request_queue에 대한 포인터를 포함할 가능성이 매우 높다. driver는 이 data 구조체를 준비하자 마자, blk_mq_init_queue()함수를 실행한다 그것은 hardware and software context를 초기화 하고 그것들 사이의 mapping을 수행한다. 초기화 루틴은 또한 대체 make_request 함수를 설정한다, 전통적인 request submission path(blk_make_request()를 포함 할것이다)를 대체하는 the multi-queue submission path(대신 blk_mq_make_request()를 포함한다. )로 대체한다. 평소처럼, 대체 make_request 함수는 blk_queue_make_request() helper로 설정된다.
Request submission
Device 초기화는 multi-queue-ready request-submission 함수인 bulk_mq_make_request()함수로 전통적인 I/O submission함수를 교체해서 multi-queue 구초제가 upper layers의 관점에서 투명하게 사용되게 한다. multi-queue block layer에 의해 사용되는 make_request 함수는 단일 hardware queue를 제원하는 driver or async request에 대해서만 per-process plugging 혜택을 볼수 있는 가능성을 포함한다. request 가 sync 이고 driver 가 적극적으로 multi-queue interface를 사용하는 경우, plugging이 수행되지 않는다. make_request 함수는 또한 request merging을 수행하여 만약 plugging이 허영되면, tasks’s plug list안에서 처음 후보자를 찾고 마지막으로 현재 CPU에 mapped된 software queue에서 찾는다. submission path에는 모든 I/O scheduling-related callback이 필요하지 않다. 마침내, make_request는 해당하는 hardware queue에게 즉시 모든 sync request를 보낸다. sync or flush request의 경우에 이 transition을 지연 시키므로 subsequent merging과 더 효율적인 dispatching이 가능하다.
Request dispatch
I/O request가 synchronous인 경우 (그래서 multi-queue block layer에서 plugging을 허용하지 않는다.) device driver로 dispatch는 같은 reuqest의 context에서 수행된다. 만약 request가 대신 async or flush이면, 그리고 task plugging이 존재하면, dispatch는 실행 될 수 있다.
a) 동일한 hardware queue와 연관된 software queue에 또 다른 I/O request를 제출하는 context
b) request submission / 실행 동안에 scheduled된 delayed work가 실행 되었을때
Multi-queue block layer의 main run-of-queue 함수는 bulk_mq_run_hw_queue()이며 기본적으로 blk_mq_ops 구조체의 queue_rq filed가 가리키는 다른 driver-specific routine에 의존한다. 이 함수는 async request에 대해 queue의 모든 실행을 지연시시키는 반면 sync request는 driver에게 즉시 전달한다. request가 sync인 경우에, blk_mq_run_queue()에 의해 호출되는 inner 함수인 blk_mq_run_hw_queue()는 먼저 현재 서비스 중인 hardware queue와 연관된 software queue을 합류한다. 모든 서비스 대상 항목들을 수집한 다음, queue_rq 함수를 사용하여 각 request를 driver에 전달하여 처리한다.
함수는 마침내, 연관된 request의 requeue or deletion로 가능한 errors들을 처리한다.
Figure 3: Functions performing request transition between different data structures.
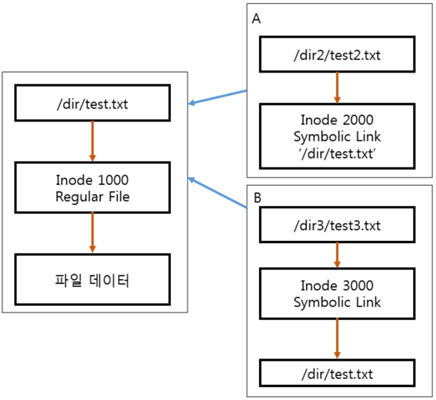
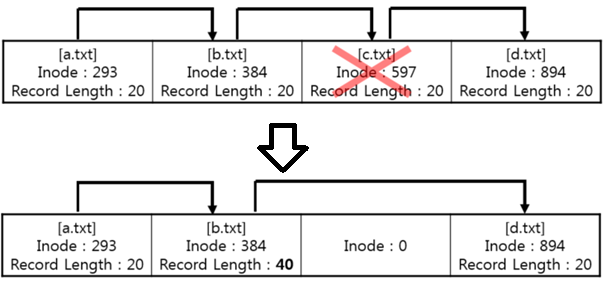
- Record Length항목은파일명의길이외에도영향을받는몇가지가있는데엔트리가생서되는시점에엔트리의크기를4의배수로맞추기위해패딩을넣거나,나중에파일삭제하는경우엔트리에도제거하는데이때실제해당엔트리가지워지는것이아니라그앞의엔트리크기를지우려는파일(or디렉토리)의엔트리크기만큼늘려서그다음엔트리를가리키도록수정한다.