무조건적으로 block layer를 거치는 것은 아님. buffered I/O를 하게 되면 block layer를 안거친게 됨
anonymous page와 page cache의 차이점
anonymous page : file과는 상관 없으며, stack, heap 같은 것이 예임
page cache: disk block이 유지되는 곳. data block의 내용일 수도 있고, inode 같은 meta 정보일 수도 있음
$ cat /proc/$$/status | grep An
task가 anonymous page를 차지하고 있는 크기 확인 법
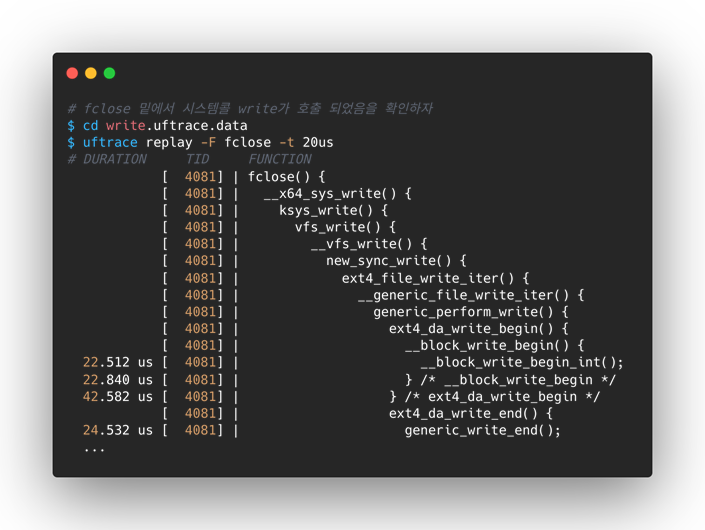
bufferd I/O의 3단계
1) write_begin: pagecache 준비
2) 유저 데이터 복사 : pagecache 쓰기
3) write_end: pagecache 더티
<buffered i/o write 실습>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
void main()
{
FILE *fp = fopen("hello.txt", "w");
if (fp) {
fprintf(fp, "hello linux filesystem\n");
fclose(fp);
sync();
}
}$ sudo uftrace record -K 30 -d write.uftrace.data ./write
$ uftrace tui (기존에는 replay로 봤는데, tui로 접었다 폈다를 할 수 있음)
fwrite 부분에 sys_write가 없는 이유는? 왜 fclose 부분에 있을까?
-> 상황마다 상이함. 어떤 경우에선 fclose에, 어떤 경우에는 fwrite에 sys_write가 존재 할 수 있음
-> fwrite는 sys_write를 호출 안하는 것이 아님

generic_perform_write는 bufferd_i/o를 실행시키는 핵심 함수

mark_buffer_dirty -> dirty bit 체크 하는 부분 (data)
mark_inode_dirty -> dirty bit 체크 하는 부분 (inode)

stat을 통해 file의 변경사항을 볼 수 있음


pagecache: 파일 관련된 내용이 저장된 곳
파일 정보 -> buffers, 파일 내용 -> cached
anonymous page와 구분해 파악하자

major fault ex) 어제 진행된 mmap 예제, 일부 영역에 있어 page fault 발생했을 경우, 근처의 page들에 대해 추가적으로 I/O를 통해 가지고 옴. ext4_read_pages(?) 부분이 있음
minor fault ex) ??? 다시 정리가 필요함
mmap test를 할때 미리 cat mmap_test.txt 을 수행해 data를 pagecache에 올린 후 test를 진행하면 I/O를 수반하지 않기 때문에 minor fault가 됨
$ vim ${linux}/arch/x86/mm/fault.c::do_user_addr_fault
major fault인지 minor인지 판단해 동작 함


write에 대한 systemcall 부분


sys_write -> ... -> __vfs_write -> .. -> ext4_file_write_iter를 호출 함

fd index 0~2 : stdin/stdout/stderr
3번 부터 파일 open을 위해 할 당 가능함
struct file을 통해 file handle 가능함
$ vim ${linux}/mm/filemap.c::generic_perform_write
buffed i/o이기 떄문에 fs/ext4/file.c::ext4_file_write_iter -> mm/filemap.c::generic_perform_write로 이어짐
첫번째 줄을 보면 address_space를 file로 부터 전달 받게 된다.

여기 안에서 실제 pagecache 동작을 하게 하는 write_begin, iov_iter_copy_from_user_atomic, write_end 등이 존재하게 된다.
-----------------------------------------------------------------------------------------------------------------------------------
read에 대해 실습
1. bufferd i/o
2. cache flush 후 i/o
#include <stdio.h>
#include <stdlib.h>
//hello linux filesystem\n
#define SIZE 24
void main()
{
FILE *fp = fopen("hello.txt","r");
char buf[BUFSIZ];
if (fp) {
fread(buf, SIZE, 1, fp);
printf("%s", buf);
fclose(fp);
}
}hello.txt 파일의 내용을 caching하기 위해 cat 수행
$ cat hello.txt실험 두개의 결과
$ uftrace replay -d read.uftrace.data | grep ext4_readpages # buffed i/o
$ uftrace replay -d read2 .uftrace.data | grep ext4_readpages # cache flush
cache flush 진행된 결과에 대해서만 ext4_readpages가 확인 된다.
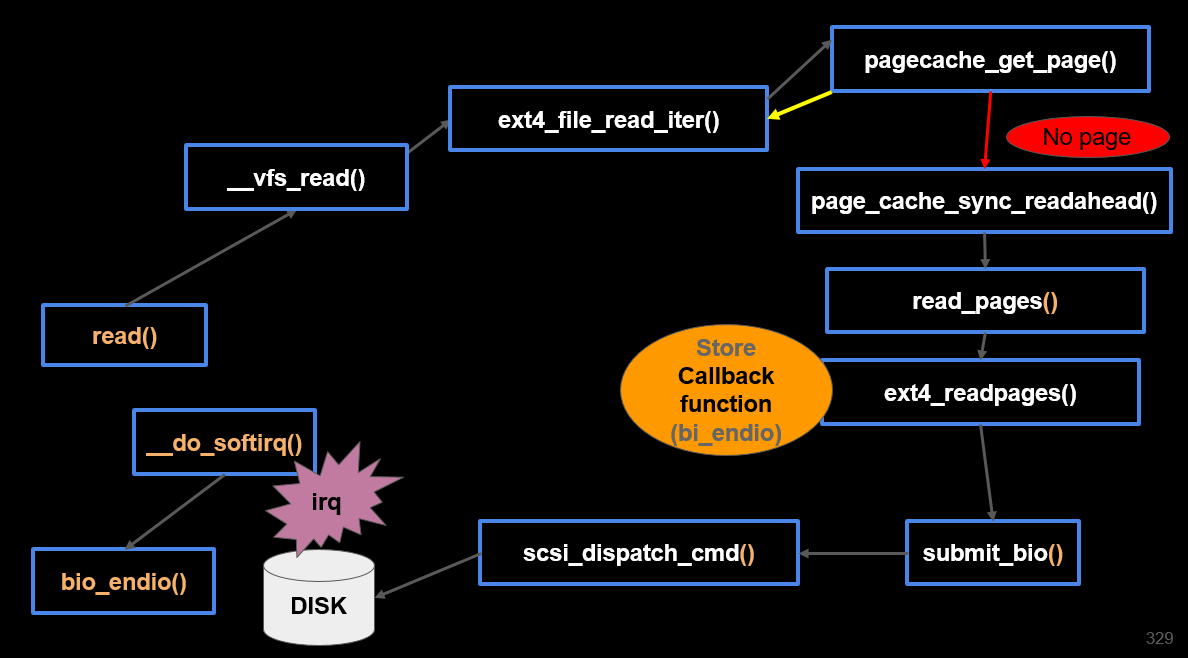
read 과정:
(0) 페이지 캐시 탐색 -> hit -> read
(1) 페이지 캐시 (X) miss
-> 페이지 캐시 준비
-> 디스크 I/O Read 요청 ext4_readpages()
-> 블록 I/O
-> 디바이스 드라이버 (scsi)
-> sleep -> IRQ -> wakeup
코드 레벨로 확인

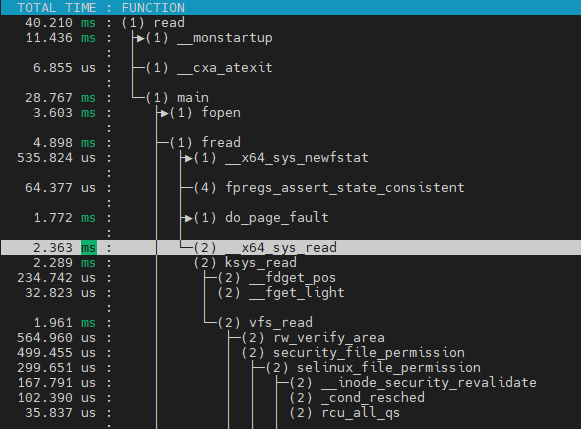




위와 같은 과저으로 sys_read에서 ext4_file_read_iter까지 이어짐
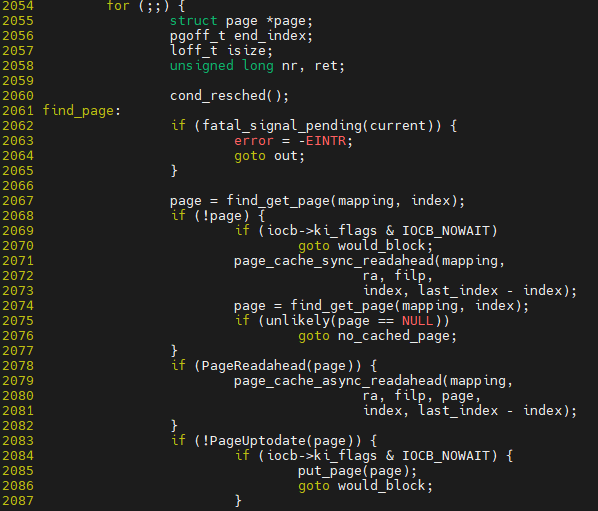
fine_get_page에서 mapping이 사용되는데, 이것은 address_space이며 이것 자체를 쓴 다는 것은 buffered i/o를 한다는 것임
if(!page)에서 page NULL인 경우 disk i/o를 호출한다는 것임

pagecache를 get했기 때문에 touch_atime으로 종료가 됨 즉, buffed i/o

반면에 cache miss의 경우 ext4에 의해 read를 하게 되며, 그 부분에 read_pages()->ext4_readpages()

cache miss의 경우 read pages 요청을 block layer을 통해 진행 후 io schdule 함수를 통해 schdule을 호출한다. schdule을 호출된다는 것은 CPU 점유를 놓는다는 것이다.(disk i/o는 오래걸리는 작업이기 때문에)

read_ahead 수행시 한번에 읽을 크기
---------------------------------------------------------------------------------------------------------------------------------
vfs에서 분기가 되는 call 흐름
vfs->proc 처리 부분
$ sudo uftrace record --force -d proc.uftrace.data -K 30 cat /proc/version
$ uftrace replay -t 1ms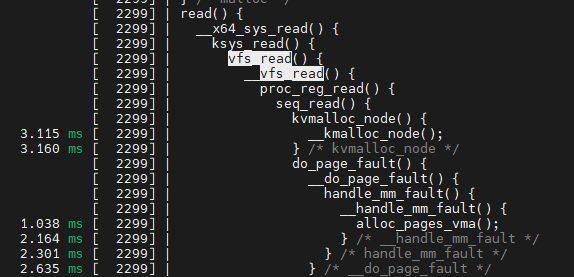
proc_reg_read()
---------------------------------------------------------------------------------------------------------------------------------
파일 open 과정
주된 목적: struct file을 준비 하는 것
struct file 준비 후 fd에 매핑해 전달 함
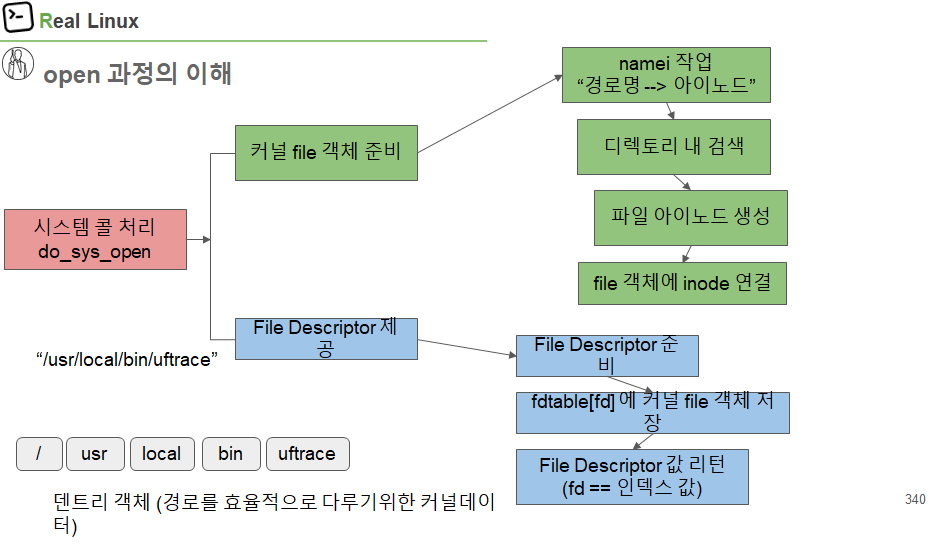
커널 file 객체 준비하는게 가장 중요함
namei.c에서 namei의 의미는 name to inode, 경로명을 inode로 변경
실습은 write했던 uftrace자료에서 open쪽 확인

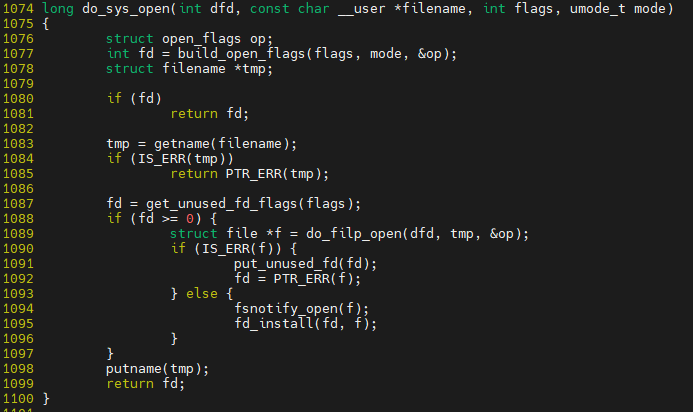
do_sys_open에 do_file_open과 fd_install이 모두 존재하며, do_file_open은 file 객체를 준비해주는 과정, fd_install은 file객체를 fd에 넣어 주는 과정
do_file_open에서 namei 과정을 하게 되는데 크게 두 가지 함 1. 이름을 dentry로 변경 -> 2. dentry를 inode로 변경

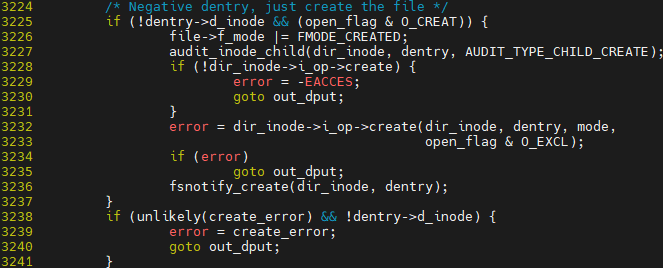
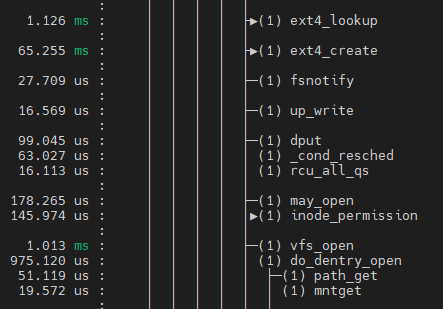
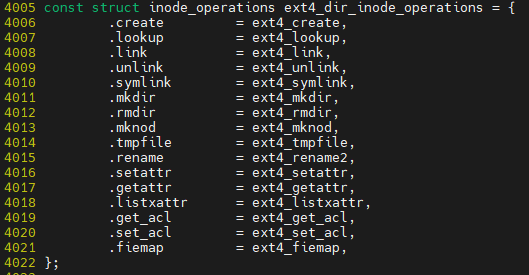
loopup_open의 역할
inode 찾은 후 없으면 create 진행되어야 함
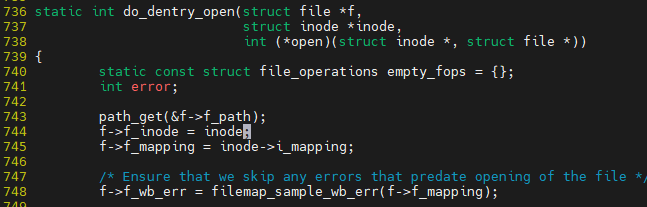
f->f_inode = inode; file 객체에 inode를 연결 하는 부분

fd_install 진행되는 부분, rcu_assing_pointer() 부분이 fdt->fd[fd]에 file 객체를 연결하는 부분임
마치 fdt->fd[fd] = file;과 유사함 추가적인 scheme들이 추가되었을 뿐
------------------------------------------------------------------------------------------------------------------------------
파일 디스크립터 기본 개수 및 최대 개수

최대 오픈 가능한 파일 개수 및 하나의 task가 오픈할 수 있는 파일 개수=

열수 있는 파일 개수를 조절해 더이상 파일을 열수 없게 함
<최대 오픈 가능한 file개수 확인 코드>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
void main()
{
FILE *fp[2048];
int i, files_max;
char filename[128];
for (i = 0; i < 2048; i++) {
sprintf(filename, "hello%d.txt", i);
fp[i] = fopen(filename, "w");
if (fp[i]) {
fprintf(fp[i], "hello linux filesystem\n");
} else {
printf("failed fd %d\n", i);
break;
}
printf("%s\n", filename);
}
files_max = i;
for (i = 0; i < files_max; i++)
fclose(fp[i]);
}
fd 1021까지만 출력된 이유는 총 1024개를 fd open할수 있으나, 기본적으로 stdin, stdout, stderr이 포함되어 있기 때문에 1021에서 에러가 발생한다.
------------------------------------------------------------------------------------------------------------------------------
리다이렉트 '>' 와 파이프 '|' 그리고 파일 디스크립터

echo "hello" > hello.txt
echo "hello"는 stdout에 출력하는 것임 그것을 dup2를 통해 hello.txt가 위치한 fd 3 혹은 4번에 write하게 되는 것임
dup2가 1번 fd를 4번으로 바꾼다.
------------------------------------------------------------------------------------------------------------------------------
Sync 과정
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > events/writeback/enable
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > options/stacktrace
$ sync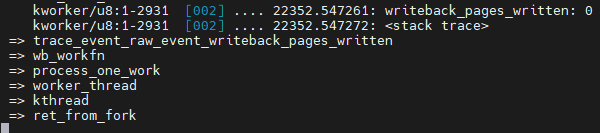
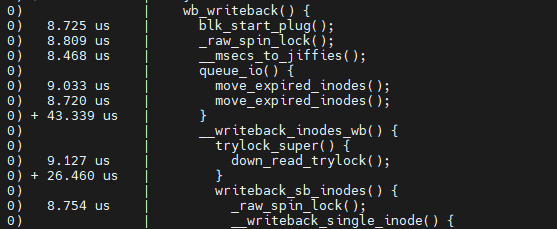
sync 후 kworker에 의해 wb 발생. wb == write back
1. wb_workfn
2. wb_do_writeback
3. wb_writeback (trace_writeback_exec)
4. __writeback_inodes_wb
5. writeback_sb_inodes
6. __writeback_single_inode (trace_writeback_single_inode_start)
7. do_writepages
--------------------------------------------------------------------------------------------------------------------------------
VFS / FS 주요 자료 구조 & 블록 디바이스 I/O

block size와 sector 사이즈 계산하기
Block 처리 과정 : blktrace를 통해서 블록 처리 과정 확인
$ sudo btrace /dev/sda > brace.data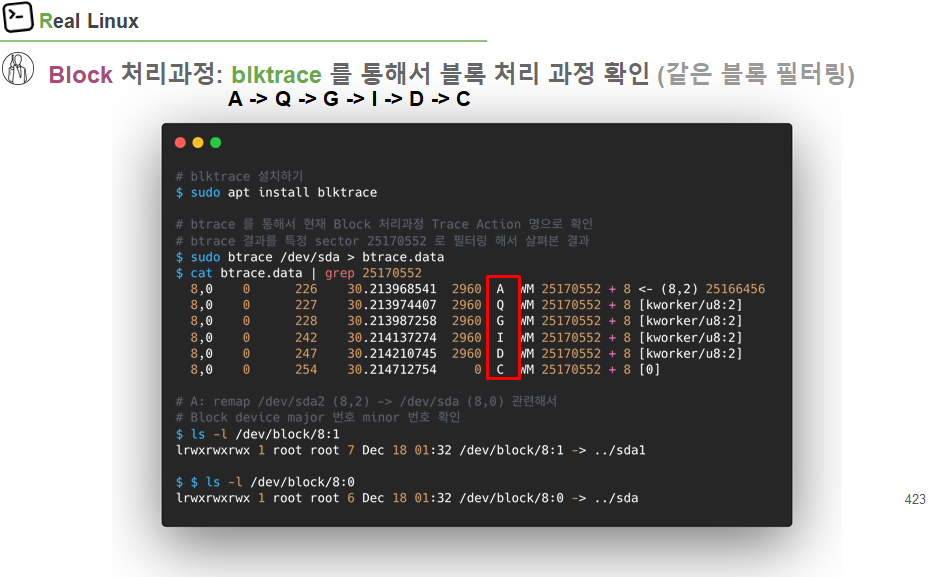
A->Q->M으로 끝난 요청은 request에 bio merge 후 끝
--------------------------------------------------------------------------------------------------------------------------------
아이노드 number와 블록 주소

inode 확인 및 inode를 통한 파일 명 확인

3183523은 data block 주소. 이 주소를 통해 data block의 내용을 읽자

blkcat과 cat의 결과는 같지만 cat은 file open을 통해 fd install까지 하고 read해서 출력하는 것이지만, blkcat은 direct i/o를 해서 출력하게 된다
<inode 찾는 스크립트>
#!/bin/bash
DEV=$1
I=$2
__STAT=$(fsstat $DEV)
_STAT=$(grep -A 4 'BLOCK GROUP INFORMATION' <<< $__STAT)
_STAT_I=$(awk '{print $NF}' <<< $(grep 'Inodes' <<< $_STAT))
_STAT_D=$(awk '{print $NF}' <<< $(grep 'Blocks' <<< $_STAT))
# Number of Inode, Data in one EXT4 group
echo "Inode/Data Blks per one Grp : $_STAT_I / $_STAT_D"
G_IDX=$[I/_STAT_I]
# Info about EXT Group
grep -A 8 "Group: $G_IDX:" <<< $__STAT
G_STAT=$(grep -A 8 "Group: $G_IDX:" <<< $__STAT)
G_I_START=$(awk '{print $3}' <<< $(grep 'Inode Range' <<< $G_STAT))
G_I_OFFSET=$((I-G_I_START))
G_I_Nth_BLK=$((G_I_OFFSET/16))
_TMP=$((G_I_Nth_BLK*16))
G_I_Nth_BLK_Idx=$((G_I_OFFSET-_TMP))
echo "Inode: $I / Group: $G_IDX / Nth Inode: $red($G_I_OFFSET) <=$I-$G_I_START"
echo "Inode BLK: $G_I_OFFSET/16=$G_I_Nth_BLK, $G_I_Nth_BLK_Idx"
G_I_BLK_START=$(awk '{print $3}' <<< $(grep 'Inode Table' <<< $G_STAT))
G_I_BLK_LOCATED=$((G_I_BLK_START+G_I_Nth_BLK))
#echo "Inode located at:" $G_I_BLK_LOCATED "+ $G_I_Nth_BLK_Idx*256 Byte"
echo "Inode located at: $G_I_BLK_LOCATED "
#OFFSET=$((G_I_Nth_BLK_Idx*256))
#echo "Dumping $G_I_BLK_LOCATED from $OFFSET"
#blkcat -h $DEV $G_I_BLK_LOCATED | grep -A 16 -w $OFFSET
hello.txt의 inode number를 통해 실제 inode block의 주소를 찾아 냄
--------------------------------------------------------------------------------------------------------------------------------
블록처리 과정 추적
$ sudo btrace /dev/sda > write.btrace.data 실행 후 아래 과정 수행
write는 vfs에서 실험했던 write 파일임

4418743을 *8해서 sector로 변경->35349944
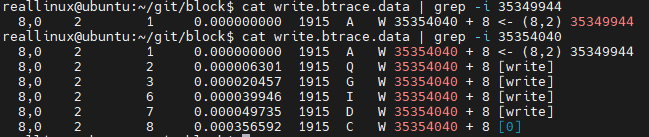
btrace에서 35349944 탐색시 (8,2)에서 remap되어 (8,0)에서 실행됨 그래서 35349944이 아닌 35354040에 대해 주소 값을 찾아야 함
35354040에 대해 결과 값을 확인 한 것
이번에는 inode block에 대해서 확인을 해보자
<inode number로 inode 정보 확인>
#!/bin/bash
DEV=$1
I=$2
__STAT=$(fsstat $DEV)
_STAT=$(grep -A 4 'BLOCK GROUP INFORMATION' <<< $__STAT)
_STAT_I=$(awk '{print $NF}' <<< $(grep 'Inodes' <<< $_STAT))
_STAT_D=$(awk '{print $NF}' <<< $(grep 'Blocks' <<< $_STAT))
# Number of Inode, Data in one EXT4 group
echo "Inode/Data Blks per one Grp : $_STAT_I / $_STAT_D"
G_IDX=$[I/_STAT_I]
# Info about EXT Group
grep -A 8 "Group: $G_IDX:" <<< $__STAT
G_STAT=$(grep -A 8 "Group: $G_IDX:" <<< $__STAT)
G_I_START=$(awk '{print $3}' <<< $(grep 'Inode Range' <<< $G_STAT))
G_I_OFFSET=$((I-G_I_START))
G_I_Nth_BLK=$((G_I_OFFSET/16))
_TMP=$((G_I_Nth_BLK*16))
G_I_Nth_BLK_Idx=$((G_I_OFFSET-_TMP))
echo "Inode: $I / Group: $G_IDX / Nth Inode: $red($G_I_OFFSET) <=$I-$G_I_START"
echo "Inode BLK: $G_I_OFFSET/16=$G_I_Nth_BLK, $G_I_Nth_BLK_Idx"
G_I_BLK_START=$(awk '{print $3}' <<< $(grep 'Inode Table' <<< $G_STAT))
G_I_BLK_LOCATED=$((G_I_BLK_START+G_I_Nth_BLK))
#echo "Inode located at:" $G_I_BLK_LOCATED "+ $G_I_Nth_BLK_Idx*256 Byte"
echo "Inode located at: $G_I_BLK_LOCATED "
#OFFSET=$((G_I_Nth_BLK_Idx*256))
#echo "Dumping $G_I_BLK_LOCATED from $OFFSET"
#blkcat -h $DEV $G_I_BLK_LOCATED | grep -A 16 -w $OFFSET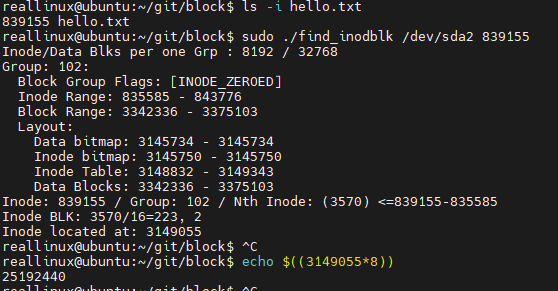

WSM :
- W : write
- S : sync
- M : Meta data
여기에서는 inode block에 대해 2번 수정이 된 것이다. 시간 대역이 다르므로
block tracepoint를 통한 추적
$ echo 1 > events/block/enable

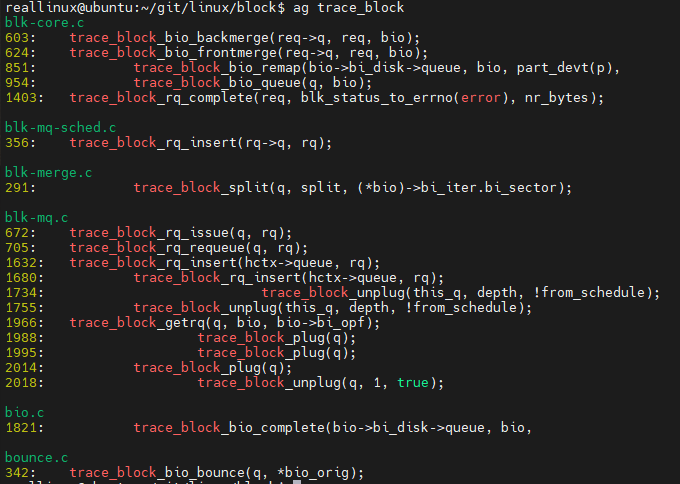
해당 부분들이 trace의 결과로 보여지는 것이다.
------------------------------------------------------------------------------------------------------------------------------
리눅스 스케줄러의 이해
커널 버전 변경하기
sudo apt install -y linux-image-5.4.0-65-generic
reboot

cgrup들에 대해 cfs에 대해 period 값 확인 및 해당 task들에 대한 할당 CPU 총시간

process의 실행한시간 runtime 값 확인
$ cat /proc/%%/sched

한 프로세스가 가질 수 있는 최소한의 period 시간
-------------------------------------------------------------------------------------------------------------------
우선순위/nice 값/weight 값 이해와 실습


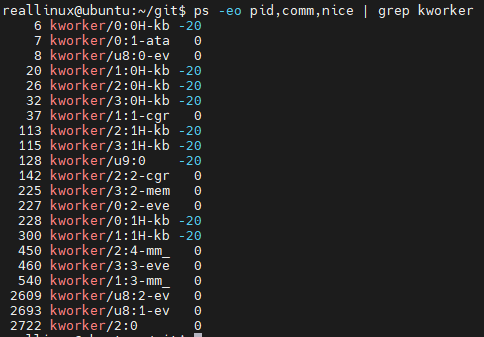
nice 값을 확인하는 방법은 원래 stat을 통해 하나씩 해결해야 함. man proc을 수행하면 어떤 값들이 어떤 의미를 가지고 있는지 알려줌
kworker의 경우 모두 우선순위기 높은 것은 아니다.

top에서 NI가 nice 값을 나타낸다.
나이스값을 변경하는 실습


원래 기본적으로 bash의 nice 값이 0이지만, nice bash를 통해 새로 bash를 생성 후 확인시 10으로 되어 있음을 확인 함
nice 값 조절도 가능함

renice를 통해 현재 사용중인 bash에 대해 nice 값을 수정 할 수 있음

nice에 매칭되는 weight 값

process에 할당된 nice 값과 weight값
저기에 보이는 weight 값은 *1024가 되어 있으므로 값/1024해야 함
echo $((90891264/1024)) = 88761 -> nice -20
--------------------------------------------------------------------------------------------------------------------------------
프로세스의 타임슬라이스(실행할 시간) 할당