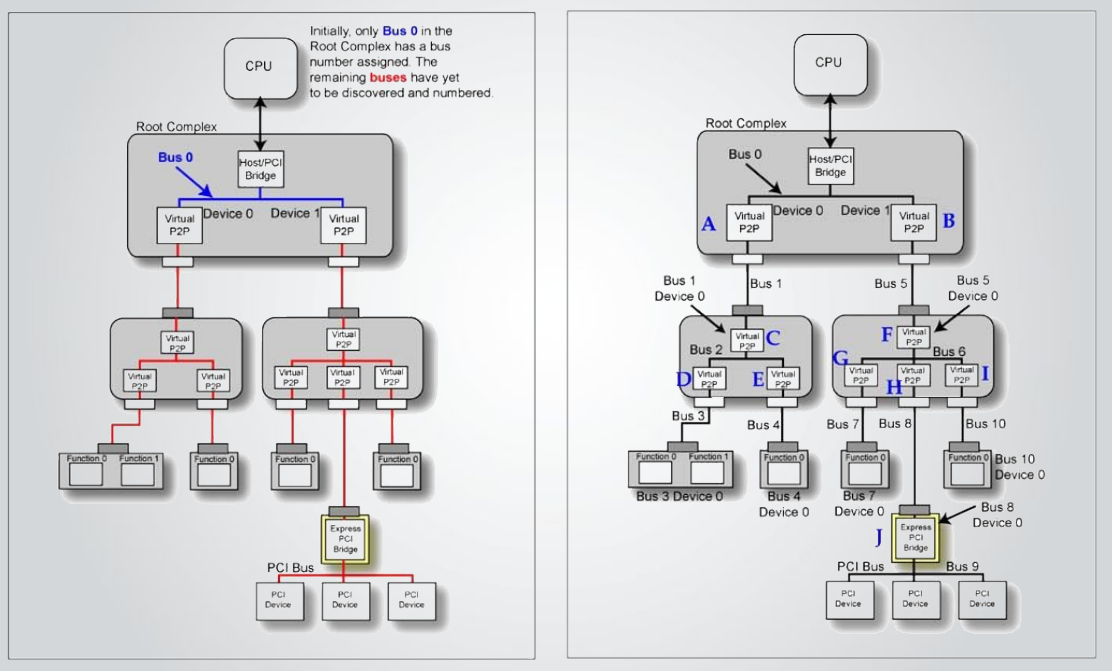
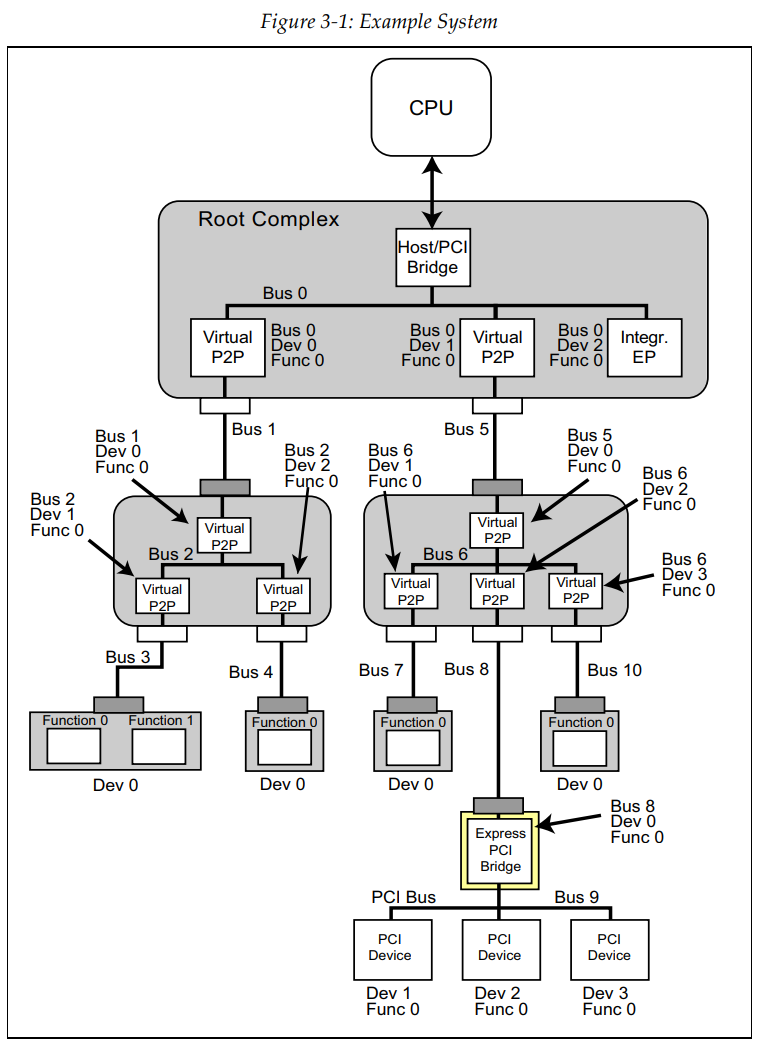
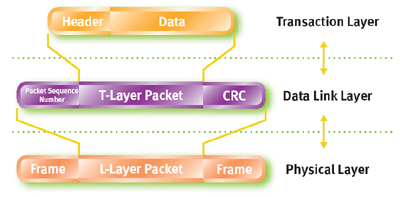
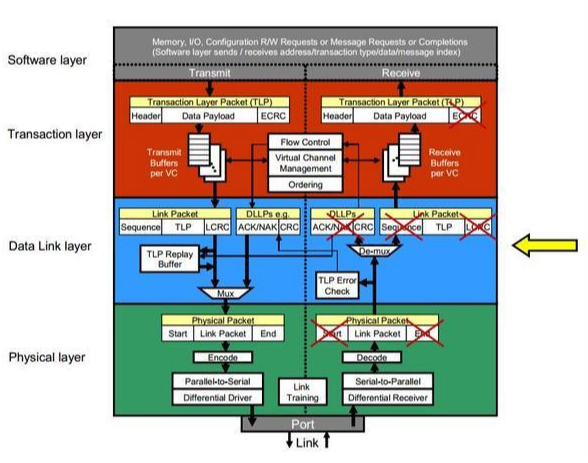
참조: http://esos.hanyang.ac.kr/?page_id=13347
http://esos.hanyang.ac.kr/?page_id=15843
주제 1. 리눅스의 대용량 메모리 관리 기법 분석
현재 PC 시장에서 DRAM 메모리의 용량은 크게 증가되었으며, 메모리 집적화 기술의 고도화로 인해 대용량 서버 환경에서는 TB 단위의 메모리까지 등장하게 되었다. 하지만 이와 같은 물리 메모리의 증가는 CPU의 하드웨어 캐시인 TLB(Translation Look-aside Buffer)의 잦은 Miss를 통해 전체적인 메모리 작업의 성능을 하락시키는 문제를 발생시켰다. 때문에 리눅스에서는 하나의 페이지의 크기를 2MB, 1GB까지 확장하도록 지원하는THP(Transparent Huge Page)기법을 제공한다. THP 기법은 하나의 TLB에서 관리할 수 있는 페이지의 크기를 늘려, 기존의 TLB로도 효율적으로 대용량 메모리를 관리할 수 있도록 하는 장점이 있다. 하지만, THP 기법은 비효율적인 메모리 할당 정책 및 페이지 할당에 걸리는 시간이 매우 크다는 단점이 존재하기에 아직 완벽한 기법이 아니다. 본 프로젝트에서는 이러한 리눅스의 THP 기법을 코드 단위로 분석하여 그 동작 방식을 이해하며, 대용량 메모리 경에서의 THP 기법 사용의 장단점을 분석한다. 본 프로젝트는 분석을 위해 Sysbench, Cloudstone, Redis, MongoDB 등 DB환경에서의 성능 분석 툴을 사용하여 Buffered I/O의 지연 시간 및 물리 메모리 사용량을 측정한다. 이러한 분석과정을 통해 리눅스에서 THP 기법의 동작 방식에 대한 장단점 파악 및 개선 방안을 고안한다. 본 프로젝트는 리눅스의 물리 메모리 관리 기법에 대한 이해를 우선할 수 있음은 물론, 리눅스 기반 대용량 메모리 시스템에 최적화 된 메모리 관리 방식을 설계하는 것을 목표로 한다.
프로젝트 완성도 : 최종 보고서, 발표 자료, 소스코드, Transparent Huge Page 개선 방안 등
자격 요건 : 자료구조, 운영체제, C (리눅스 커널 사전지식 불필요)
주제 2. EXT4의 Buffered Write 성능 개선
사용자 프로세스가 특별한 플래그(O_DIRECT, O_SYNC) 없이 일반적인 방법으로 열린 파일에 대해서 쓰기(write())를 수행하면, 리눅스 커널은 사용자가 쓰기를 요청한 내용을 디스크 내 파일에 바로 쓰지 않고, 메모리 내 페이지 캐시에서 페이지를 할당 받아 페이지에 내용을 쓴다. 해당 페이지는 더티 페이지로 구분되고, 추후 커널 쓰레드에 의해 파일에 쓰여진다. 이를 Buffered 쓰기라고 한다. Buffered 쓰기를 사용함으로써 사용자 프로세스는 쓰기(write())를 빠르게 수행할 수 있다. 하지만, 사용자 프로세스가 4KB Buffered 쓰기를 과도하게 하면, write() 시스템 콜의 Latency가 1초 이상으로 증가하는 것을 볼 수 있다. EXT4 파일 시스템에서 write() 시스템 콜의 Latency 증가 원인은 쓰기를 수행할 페이지를 할당하는 ext4_write_begin():fs/ext4/inode.c 함수와, 해당 더티 페이지로 구분하고, Buffered 쓰기 동작을 마무리하는 ext4_write_end():fs/ext4/inode.c 함수이다. 본 프로젝트에서는 write() 시스템 콜 Latency 증가의 원인이 되는 두 함수(ext4_write_begin():fs/ext4/inode.c, ext4_write_end():fs/ext4/inode)의 동작을 분석하고, 해당 함수의 동작 중 어떤 부분이 Latency 증가 원인인지 파악 후, 원인이 되는 동작이 write() 시스템 콜 Latency 증가에 영향을 끼치지 않도록 수정하는 방안을 고안하여 수정한다. 그리고, 수정한 EXT4 파일 시스템과 수정하지 않은 기존의 EXT4 파일 시스템에서 동일한 실험(30 Gbyte 이상의 Buffered 쓰기)을 통해 write() 시스템 콜의 지연 시간을 측정하여 성능향상을 확인한다.
프로젝트 완성도 : 최종 보고서, 발표자료
자격 요건 : 자료구조, 운영체제, C (리눅스 커널 사전지식 불필요)
주제 3. EXT4, F2FS, XFS에서의 fsync() 동작 및 성능 분석
fsync()는 파일시스템의 dirty block을 디스크로 플러시 하는 함수이다. 리눅스 시스템 컬중 가장 중요하고 시간이 많이 소요되는 연산이다. fsync()는 입출력 스케쥴링, 파일 시스템 저널링등 모든 분야에 다 걸쳐있다. 본 프로젝트에서는 ext4, f2fs, xfs 파일 시스템의 fsync() 알고리즘을 분석 비교 한다. 그리고, 4KByte 임의 쓰기 실험을 통해 장단점을 비교 분석해 보기로 한다. 분석은 성능과함께 입출력 트레이스를 출력한다. 리눅스 커널의 심도있는 이해를 위한 매우 좋은 주제이다.
프로젝트 제출물 : 최종 보고서, 발표자료
자격 요건 : 자료구조, 운영체제, C (리눅스 커널 사전지식 불필요)
주제 4. F2FS 파일 시스템의 세그멘트 클리닝 분석 및 개선
F2FS는 플래시 전용으로 개발된 로그기반 파일 시스템이다. 현재 화웨이사의 안드로이드 스마트폰인 P9, 구글 NEXUS 9 태블릿등에 탑재되어 시판되고 있다. 로그기반 파일 시스템은 무효화된 블럭을 소거하는 비용이 매우 높은 것으로 알려져있다. 본 프로젝트에서는 F2FS의 GC 알고리즘을 분석하고, 블록을 효율적으로 분리하는 알고리즘을 개발한다.
프로젝트 완성도 : 최종 보고서, 발표 자료
자격 요건 : 자료구조, 운영체제, C (리눅스 커널 사전지식 불필요)
주제 5. 리눅스 블록 계층의 멀티 큐 메커니즘 분석 및 개선
오늘날 컴퓨터 시스템에서 저장 장치는 HDD에서 보다 빠른 SSD로 대체되고 있고, 더 나아가 최근에는 PCIe를 이용하는 NVMe(Non-Volatile Memory Express)를 저장 장치로 효율적으로 사용하기 위한 연구가 활발히 진행되고 있다. NVMe는 최대 64K개의 하드웨어 큐를 제공하여, 많은 I/O 요청을 한꺼번에 병렬로 처리하는 것이 가능하다. 리눅스는 이러한 하드웨어 멀티 큐를 사용하는 저장 장치를 지원하기 위해 Multi-Queue block layer를 제공한다. 본 프로젝트에서는 리눅스의 Multi-Queue block layer를 제안한 “Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems” 논문을 통해 Multi-Queue block layer의 구조를 이해하고, Multi-Queue block layer 소스코드(block/blk-mq*)와 Multi-Queue block layer를 사용하는 디바이스 드라이버(drivers/nvme/*)를 분석하여I/O 처리 흐름을 파악한다. 마지막으로 IOZone, Mobibench, Filebench 등의 I/O 벤치마크 툴을 사용하여 Single-Queue와 Multi-Queue의 latency를 측정하고, 측정한 값이 위 논문에서 제시하는 성능과 차이가 있는지 비교 분석하는 것을 최종 목표로 한다. Multi-Queue block layer 분석은 리눅스 커널의 블록 계층을 심도있게 이해할 수 있는 좋은 주제이다.
프로젝트 완성도 : 최종 보고서, 발표 자료
자격 요건 : 자료구조, 운영체제, C (리눅스 커널 사전지식 불필요)
주제 6. 리눅스 I/O 스케줄러 분석 및 개선
리눅스 운영체제의 I/O 스케줄러와 다양한 입출력 조건에 따른 입출력 성능의 상관관계를 분석한다. 리눅스는 파일 시스템에서 요청한 입출력을처리(Merging, Sorting)하기 위해 CFQ, Deadline, Noop 등 다양한 스케줄링 기법을 제공하고 있으며 I/O 스케줄러는 각각 장*단점을 가지고 있다. 예를 들면, CFQ 스케줄러의 경우, I/O 처리에 있어서 공평성(Fairness)를 제공하지만 I/O 처리의 지연 시간(Response time)이 비교적 길다는 단점이 있으며 반대로 Deadline 스케줄러는 I/O 지연을 최소화할 수 있으나 I/O의 공평성을 제공하지는 못한다. 본 프로젝트에서는 스케줄러의 입출력 처리 과정을 코드 레벨(linux/block/blk-core.c, cfq-iosched.c, deadline-iosched.c, noop-iosched.c)로 확인하고 실제 성능 측정을 통해 I/O 스케줄러가 수행되는 입출력 조건(ex> Storage type, Workload 등)이 실제 I/O 처리 과정에 끼치는 영향을 분석한다(사용 벤치마크 툴: IOZone, Mobibench, Filebench). 또한 분석 결과를 근거로각 I/O 스케줄러의 처리 기법 상의 장*단점을 분석하고 개선안을 도출하여I/O 스케줄러의 성능을 향상시키는 것을 목적으로 한다.
프로젝트 완성도 : 최종 보고서, 발표 자료, 소스코드
자격 요건 : 자료구조, 운영체제, C (리눅스 커널 사전지식 불필요)
주제 7. 안드로이드를 위한 리눅스 메모리 매니저 분석 및 개선
리눅스 운영체제의 메모리 할당기는 안드로이드에는 적합하지 않은것으로 알려져있다. 때문에 많은 내부 파편화가 발생하고 메모리가 낭비되는 것으로 알려져 있다.파편화란, 메모리 내의 빈공간이나 자료가 여러 개의 조각으로 나뉘는 현상을 말한다. 데이터의 크기가 다양하기 때문에 발생하는 현상으로, 파편화가 심할 경우 성능 저하가 발생하고, 여유 공간이 충분히 있어도 할당이 실패하는 현상이 발생할 수도 있다. 본 주제에서는 리눅스의 메모리 할당기 작동을 심도있게 분석하고, 안드로이드 상에서 물리메모리가 할당되는 과정을 살펴본다. 본 프로젝트는 리눅스 운영체제의 메모리 매니저의 장단점을 분석하고, 메모리 할당, 해제, 파편화 등을 분석하는 것을 목표로 한다. 리눅스의 메모리 할당 기법을 심도있게 파악하는 매우 좋은 기회이다.
프로젝트 완성도 : 최종 보고서, 발표 자료, 소스코드, 메모리 분석 결과 등
자격 요건 : 자료구조, 운영체제, C (리눅스 커널 사전지식 불필요)
주제 8. SQLite용 저널모드 분석 및 개선
SQLite는 안드로이드, 아이폰, 타이젠, 파이어폭스등 다양한 모바일 기기에서 공통적으로 사용되는 오픈소스 임베디드 데이타베이스이다. 오픈소스 장점으로 인해 광범위하게 사용되고 있다. SQLite는 비효율적인 저널링 동작으로 인해 과도한 입출력을 발생시킨다. 스마트폰 업계에서는 SQLite의 입출력 작동을 효율화 시키는 것을 매우 중요한 주제로 삼고 있다. 본 주제에서는 SQLite의 저널 모드에 대해 학습하고, 가능한 개선 방법을 모색하도록 한다.
주 : 안드로이드 디바이스 지급
프로젝트 완성도 : 최종 보고서, 발표 자료, 소스코드, SQLite 성능 개선 방안 등
자격 요건 : 자료구조, 운영체제, C (안드로이드 사전지식 불필요)
주제 9. SSD 시뮬레이터 개발
플래시 기반의 SSD는 현대 저장장치기술의 핵심이다. 새로운 저장장치 알고리즘을 개발함에 있어서 새로운 SSD기술을 효율적으로 개발하기 위해서는 하드웨어 개발 이전에 시뮬레이터를 통해서 개발된 기술의 유효성을 검증하는 것이 필수이다. 본 과제에서는 한양대학교에서 개발하여 현재 널리 사용되고 있는 오픈소스 시뮬레이터인 VSSIM 을 개선한다. VSSIM은 오픈 소스 기반 SSD 이뮬레이터이다. SSD의 채널/웨이등을 변경할 수 있고, 이와더불어 다양한 SSD의 매핑 알고리즘과 Garbage Collection 알고리즘을 적용할 수 있다. 이를 다음과 같이 개선한다. 본 주제에서는 SSD용 시뮬레이터 VSSIM에 대해서 학습하고, 다양한 개선점을 모색한다.
– 최신 qemu로 포팅
– 다중 쓰레드 지원
– PCIe 지원
주 : 오픈소스 활동
프로젝트 완성도 : 최종 보고서, 발표 자료, 소스코드, 알고리즘, 성능 개선 방향 등
자격 요건 : 자료구조, 운영체제, C, 핀토스 사전지식 필요
주제 10. MongoDB 분석및 개선
mongdb는 현재 다양한 웹사이트에서 사용되는 효율적인 데이타베이스 이다. 블로그, 게임아이템 저장을 위해서 사용되는 가장 대중적인 자료구조이다. 몽고 DB의 핵심인 LSM tree가 어떤것인지 살펴보고 그의 동작을 분석해본다. LSM tree 가 많이 사용되는 Redis, Cassendra등의 성능을 분석한다.
프로젝트 완성도 : 최종 보고서, 발표 자료등
자격 요건 : 자료구조, 운영체제, C (안드로이드 사전지식 불필요)