

프로세스의 타임슬라이스(실행할 시간) 할당
process에 대해 period를 할당하는 것이 아닌, 가중치와 함께 계산되어 할당 하게 됨
timeslice = period (총시간) x se.load.weight (현재 프로세스 가중치) / cfs_rq->load.weight (총 가중치, 현재 동작중인 모든 프로세스의 가중치 합)
프로세스들이 많아 지면, timeslice 값이 점점 작아지게 되는데 그 부분에 대해 최소 보장을 하기 위한 것이 sched_mind_granularity임
------------------------------------------------------------------------------------------------------------------------
스케줄러 Virtual Runtime란?
vruntime = runtime(실제실행시간) * 평균 가중치 (nice 0 기준) / 나의 가중치 (se.load.weight)
virtual runtime이 작은 것을 선택해 실행시킨다.
정규화 함으로 이것을 통해 우선 순위를 정할 수 있다.
정규화 됨으로 실제 runtime과는 다른 값을 가진다.
vruntime 확인 방법
$ cat /proc/$$/sched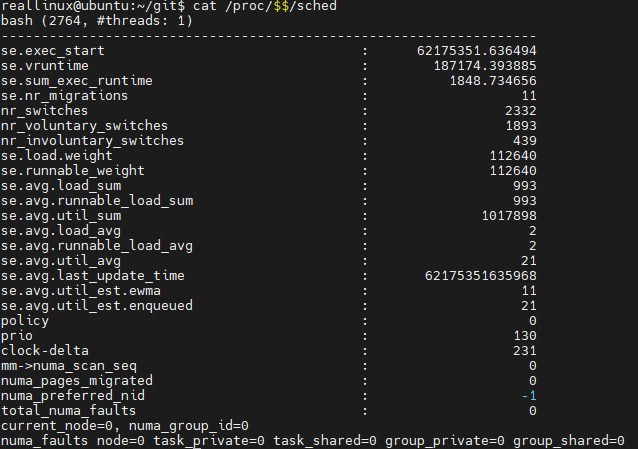
se.vruntime을 확인하면 된다.
------------------------------------------------------------------------------------------------------------------------
스케줄러 구성과 역할
리눅스 스케줄러 구성요소 4가지
1) scheduler_tick: cpu timer irq 마다 타임슬라이스 체크 및 LB 시도
2) schedule: next process 선택 및 context swtich
3) try_to_wake_up(ttwu): sleep 중인 특정 프로세스 wake up
4) load_balance: timer irq마다 cpu들 사이 런큐 로드밸런싱
------------------------------------------------------------------------------------------------------------------------
scheduler_tick 동작 과정
: CPU timer 입터럽트에 맞춰 타임슬라이스 체크 및 로드밸런싱
schduler_tick 하위에 3가지 동작
1) update_curr() : 실행한시간 계산
2) check_preempt_tick() : 선점 여부 확인 (타임슬라이스 소진 / 우선순위 체크)
3) trigger_load_balance() : CPU들 사이 로드밸런싱
$ vim ${linux}/kernel/sched/core.c::scheduler_tick

cfs scheulder를 사용한다고 가정 함

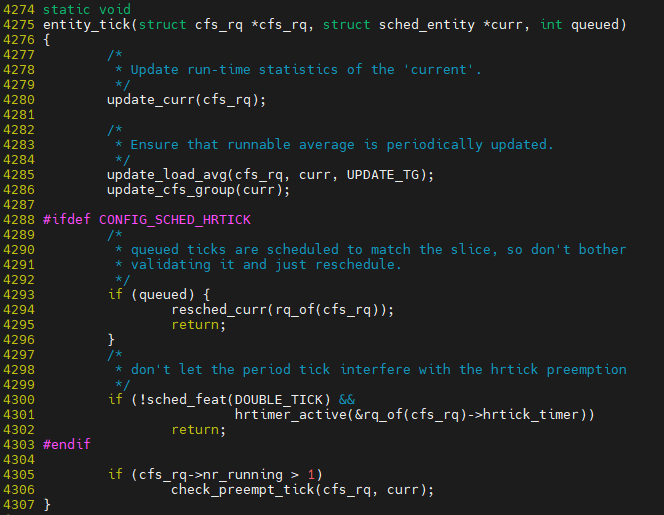
entitiy_tick이 핵심
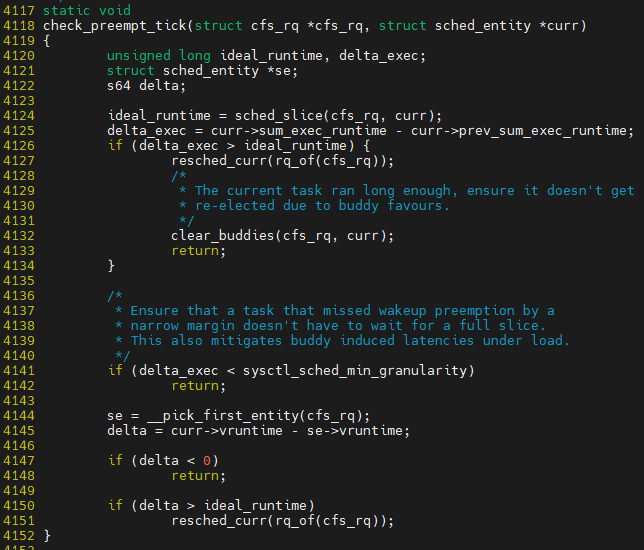
__pick_first_entity()는 현재 task보다 더 우선적으로 실행되어야 할 entry가 존재하는지 확인 하는 부분
만약 존재 한다면, reschdule 진행
------------------------------------------------------------------------------------------------------------------------
schedule 동작 과정
CPU를 놓기위해 next 프로세스 선택 및 context switch
schduler 하위 2가지 동작
1) pick_next_task(): 최소 vruntime task 선택
2) context_switch(): 다음 task가 CPU 점유
$ vim ${linux}/arch/x86/entry_64.S

interrupt가 시작되는 부분
이 부분이 끝난 이후에 user space로 돌아 갈 것인지, kernel mode에서 돌아 갈 것인지 나와 있음
retint_user / retint_kernel

$ vim ${linux}/arch/x86/entry_64.S
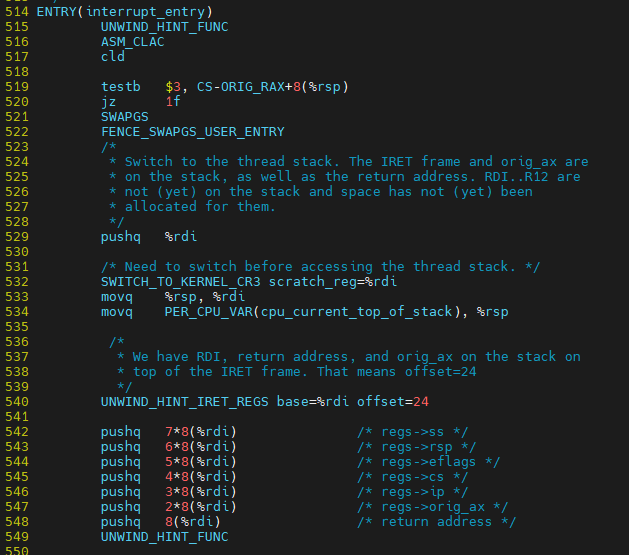
인터럽트로 인해 커널 모드 전환 후 Kernel stack (tsk->stack)에 register들을 저장 하는 과정
kernel stack에 register들을 저장 하는 큰 두 가지 예) 인터럽트, ???
vim ${linux}/kernel/sched/core.c::schedule()

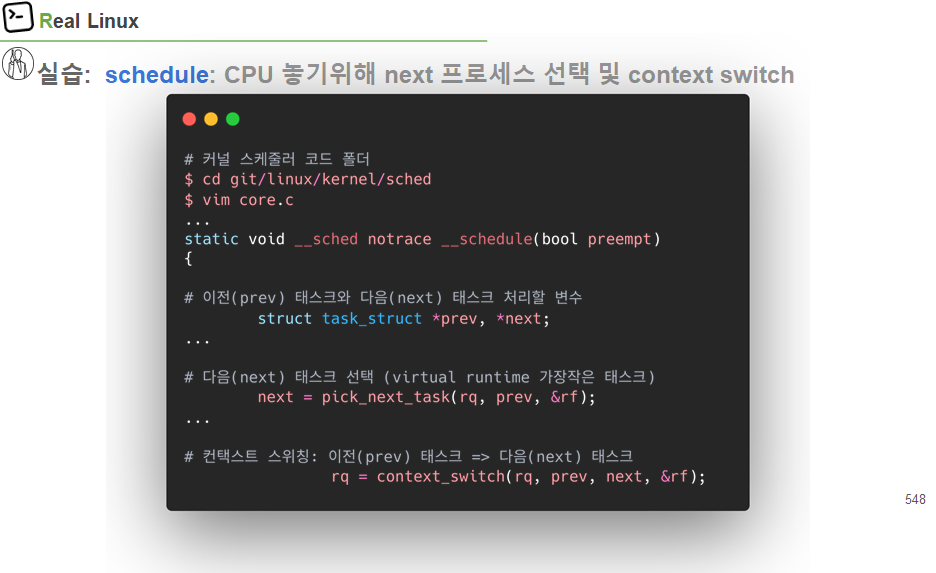
schedule() -> __schedule()

swtich_to: hw적으로 register를 변경함 prev에서 next로
기존에 실행된 적이 있던 task의 경우 현재 switch_to에서 context swtich 되었으므로, 다시 돌아 실행을 위해 context switch된 경우 barrier부터 시행을 하게 된다.
만약 처음 실행되는 task이라면, tet_from_form부터 시작이 된다.
finish_task_switch가 마무리 한다.
------------------------------------------------------------------------------------------------------------------------
try_to_wakt_up 동작 과정
대부분 interrupt 처리 과정에서 많이 발생 됨
기다리던 이벤트(ex. 패킷 도착)에 맞춰서 특정 process를 깨우는 과정에 대해 실습
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > events/sched/sched_wakeup/enable
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > options/stacktrace
interrupt가 do_IRQ로부터 발생 함. 패킷이 도착했기 떄문에 interrupt가 발생 한 것
data 받았을 경우 동작하는 것이 rx 동작
sock_def_readable -> 읽을 수 있는지 판단 후에 task에 대해 wake up을 수행 함
바로 실행되는 것은 아니고 runqueue에 enqueue 되는 것임
runqueue는 cpu마다 있으며, runqueue에 enqueue 되는 과정과 dequeue 되는 과정들에 대해 실습해 볼 것 임
fork했을시 runqueue에 enqueue하게 됨. 혹은 sleep된 것이 wake-up 되었을떄 runqueue에 enqueue함
root@ubuntu:/sys/kernel/debug/tracing# echo 'p:enqueue_task_fair enqueue_task_fair' > kprobe_events
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > events/kprobes/enqueue_task_fair/enable
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > options/stacktrace

처음 fork()로 process가 생성되는 경우
echo 'p:dequeue_task_fair dequeue_task_fair' > kprobe_events
echo 1 > events/kprobes/dequeue_task_fair/enable
echo 1 > options/stacktrace
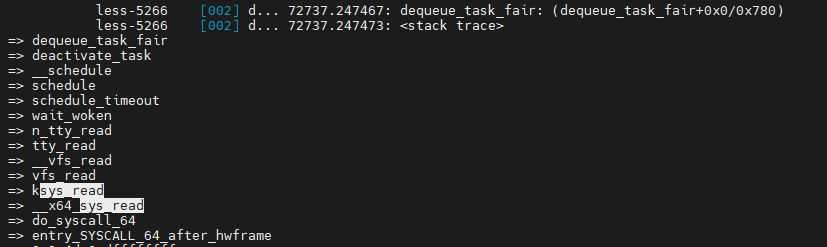
dequeue한 이유는 I/O가 오래걸려 schedule 호출하고 I/O완료를 기다리는 queue로 돌아갔음
wait queue에 enqueue 후 dequee 시나리오 이해
$ vim ${linux}/net/core/sock.c::sk_wait_data()
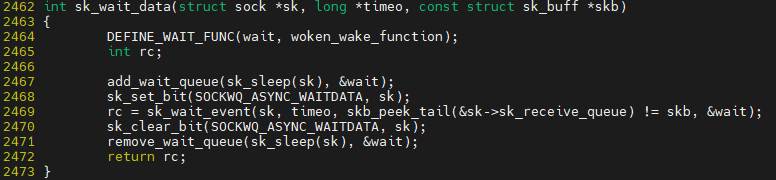
add_wait_queue에 task를 wait_queue에 enqueue하게 된다.
sk_wait_event()가 schdule()를 호출해서 sk_wait_event()에서 dequeue를 통해 cpu를 놓게 된다
sk_wait_event()후 cpu를 놓게 되고, sleep에 빠져 있음. 그리고 이에 대한 I/O 응답이 와서 TCP layer를 타고 올라오며, sock_def_readable를 통해 읽을 수 있을때 그때 wake-up을 하게 되는데 그때 wake-up 된 후 sk_clear_bit부터 다시 실행이 된다. sk_clear_bit시점에 wait queue에도 runqueue에도 task가 존재하므로, remove_wait_queue를 수행해 task에 대해 제거하게 된다.
$ vim ${linux}/net/core/sock.c::sock_def_readable()
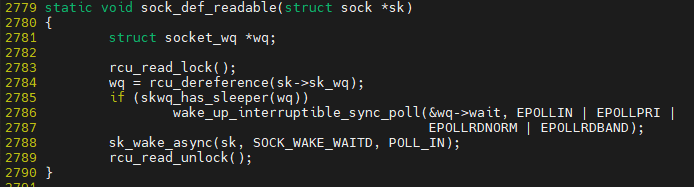
여기 부분에서 wake up이 수행되는 것이다.
------------------------------------------------------------------------------------------------------------------------
load_balance 동작 과정
timer irq마다 CPU들 사이 runqueue laod balacing
3가지 동작
1) find_busiest_queue(): 가방 바쁜 런큐 찾기
2) detach_tasks() : 넘쳐나는 태스크 빼내서
3) attach_tasks() : 여유로운 런큐에 태스크 넣기
$ vim kernel/sched/core.c::scheduler_tick() -> trigger_load_balance()

raise_softirq()가 flag만 set해 놓는 것임. 나중에 load_balancing을 호출해라
$ vim kernel/sched/fair.c::load_balance()

find_busiest_queue -> detach_tasks -> attach_tasks
디테일하게 살펴보면, runqueue들에 대한 정보들을 모두 가져와서 처리 하게 됨
------------------------------------------------------------------------------------------------------------------------
선점 Preempt의 과정

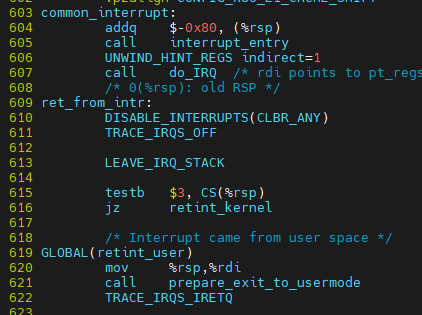
interrupt 처리 (do_IRQ) 후 복귀 지점은 ret_from_intr 위치임
여기에서 user모드로 갈 것인지, kernel로 복귀할 것인지 나와 있음
CS는 code semgment를 나타낸며, CS(%RSP)의 값이 3이면 user mode를 나타내며, user mode로 jump. 3이 아니라면 kernel mode로 jump하게 된다.
$ vim ${linux}/arch/x86/entry/common.c::prepare_exit_to_usermode
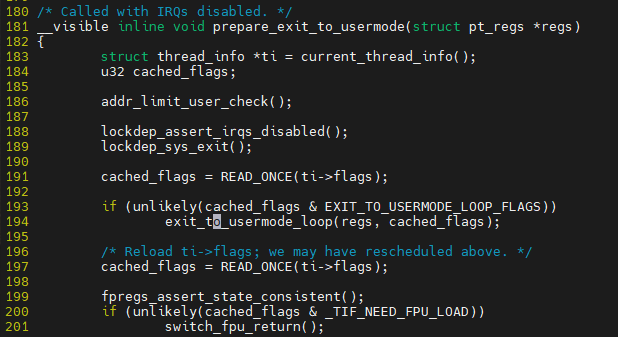
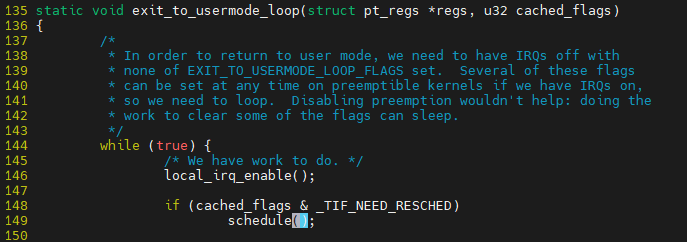
scheduled_tick에서 FLAG 설정한다고 말했었는데 그것을 판단해 선점이 가능한지를 판단한다.
interrupt나 예외처리가 없다면, 선점도 불가능하다. 선점은 interrupt나 예외처리에 의해 가능하다.
interrupt가 발생중에 interrupt가 또 발생한다? 허용하지 않는다.
(user코드로 돌아 가는 곳임)
$ vim ${linux}/arch/x86/entry/entry_64.S::common_interrupt

PER_CPU_VAR 계산 후 0이면, 선점 가능하고, preemp_schdule_irq로 들어가게 됨
------------------------------------------------------------------------------------------------------------------------
시그널 처리 - Generate(생성) / Deliver (처리)
top 프로세스 시그널 전송 처리 과정

kill에 대한 signal 번호
top에 대해 signal로 강제종료 하는 실습
$ sudo uftrace record -d kill_sig.uftrace.data --force -K 30 kill -9 5507
5507은 top에 대한 pid
kill은 sig queue까지 전송까지만 한 것임 (generate)

앞에서는 generate에 대해서만 확인한 것임. 이번에는 deliver 과정에 볼 것임
top 프로세스 시그널 받고 처리(deq:deliver) 과정
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > events/signal/enable
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > options/stacktrace
root@ubuntu:/sys/kernel/debug/tracing# pidof top
5574
root@ubuntu:/sys/kernel/debug/tracing# echo 5574 > set_event_pid
root@ubuntu:/sys/kernel/debug/tracing# echo > trace
root@ubuntu:/sys/kernel/debug/tracing# cat trace_pipe
$ kill -9 5574
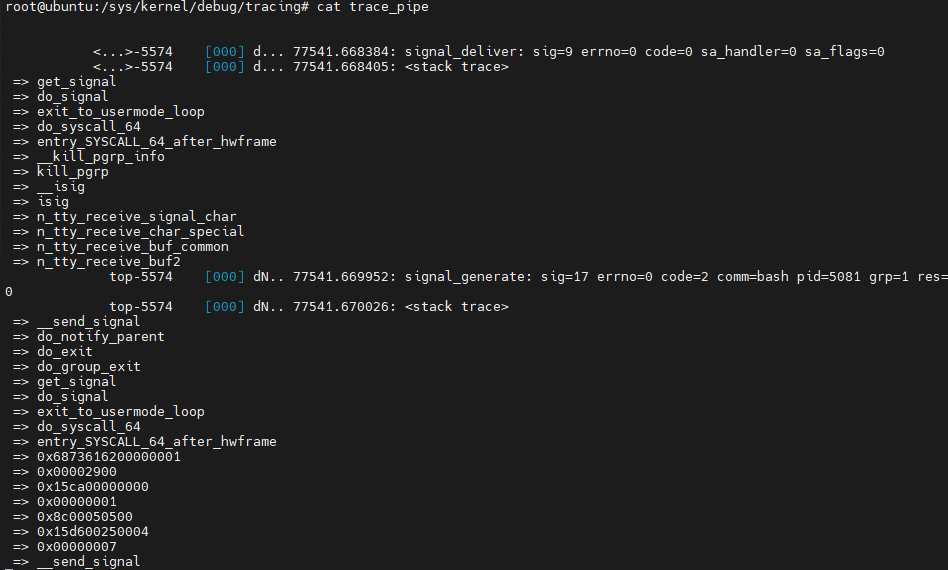
user mode로 전환되는 타이밍에서 signal 처리를 수행하는 것임
밑에 generate가 호출됨

왜 generate가 호출되는가?? sig 17번이 호출되는 것임.
sig 17은 SIGCHILD임.
즉, child가 parent에게 signal 번호 17번을 전달 함 pid 5081은 top이 실행되었던 bash의 pid임
------------------------------------------------------------------------------------------------------------------------
시그널 처리 과정 커널 코드 분석
#include <unistd.h>
#include <stdlib.h>
#include<stdio.h>
#include<signal.h>
void handle_sigint(int sig)
{
printf("Caught signal %d\n", sig);
}
int main()
{
signal(SIGINT, SIG_IGN); // Ignore SIGINT
signal(SIGINT, SIG_DFL); // Use default SIGINT
signal(SIGINT, handle_sigint); // Set a signal handler
while (1) {
sleep(1);
printf("Process Running ...\n");
}
return 0;
}
$ ./signal_test
$ pidof signal_test
$ kill -SIGINT "PID"
$ vim ${linux]/kernel/signal.c
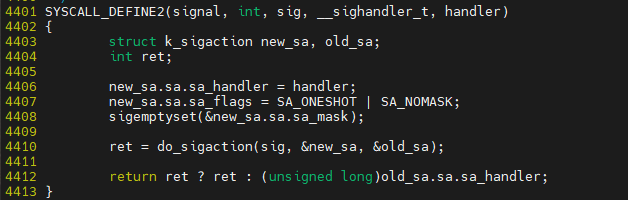

do_sigaction 내에서 sighand->action[sig-1]에서 sighan_struct 배열을 가지고 오고 *k = *act를 통해 sig handle을 추가 한다.
send_signal() 부분에 대해 실습 과제 정리 놓침
$ ${linux}/arch/x86/entry/common.c::exit_to_usermode_loop
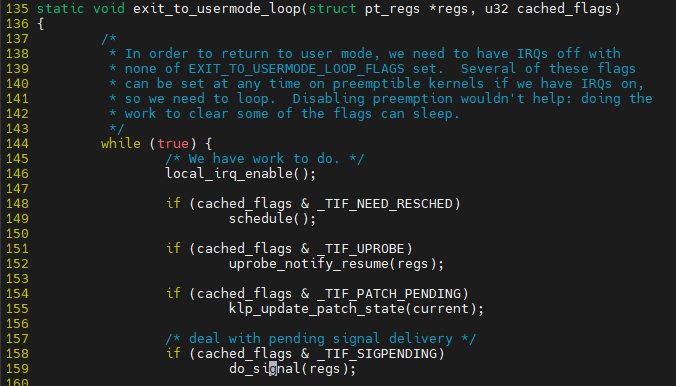


pending되어 있는 queue에서 signal을 끄집어 냄
sig_kernel_ignor 무시가 필요하면 아무것도 안함
기본 처리가 되는 부분은 do_grouop_exit임
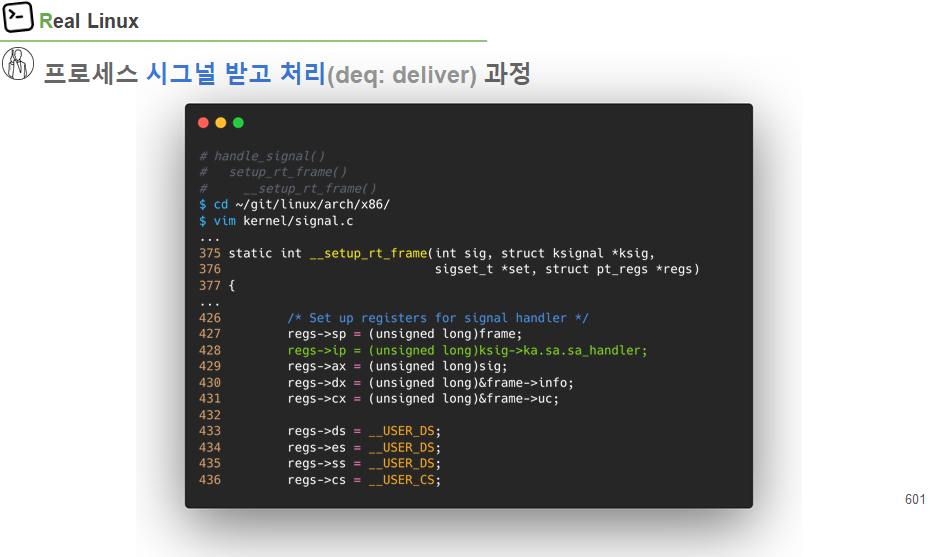
user code에서 등록한 등록된 signal에 대해 처리
------------------------------------------------------------------------------------------------------------------------
리눅스 OS이해와 네트워크(TCP/IP) 동작 분석
$ vim net/socket.c

vfs처럼 fd_install을 통해 file을 만든다.
server / client 실습
<client>
#include <stdio.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#define MAXLINE 1024
int main(int argc, char **argv) {
struct sockaddr_in serveraddr;
int server_sockfd;
int client_len;
char buf[MAXLINE];
if((server_sockfd = socket(AF_INET, SOCK_STREAM, 0)) == -1) {
perror("error : ");
return 1;
}
serveraddr.sin_family = AF_INET;
serveraddr.sin_addr.s_addr = inet_addr("127.0.0.1");
serveraddr.sin_port = htons(4000);
client_len = sizeof(serveraddr);
if(connect(server_sockfd, (struct sockaddr*)&serveraddr, client_len) == -1) {
perror("connect error : ");
return 1;
}
memset(buf, 0x00, MAXLINE);
read(0, buf, MAXLINE);
if(write(server_sockfd, buf, MAXLINE) <= 0) {
perror("write error : ");
return 1;
}
memset(buf, 0x00, MAXLINE);
if(read(server_sockfd, buf, MAXLINE) <= 0) {
perror("read error: ");
return 1;
}
close(server_sockfd);
printf("server:%s\n", buf);
return 0;
}<server>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/types.h>
#include <sys/socket.h>
#define BUFF_SIZE 1024
int main(void){
int server_socket;
int client_socket;
int client_addr_size;
struct sockaddr_in server_addr;
struct sockaddr_in client_addr;
char buff_rcv[BUFF_SIZE+5];
char buff_snd[BUFF_SIZE+5];
server_socket = socket(PF_INET, SOCK_STREAM, 0);
if(-1 == server_socket){
printf( "server socket 생성 실패n");
exit( 1);
}
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(4000);
server_addr.sin_addr.s_addr= htonl(INADDR_ANY);
if(-1 == bind(server_socket, (struct sockaddr*)&server_addr, sizeof(server_addr))){
printf( "bind() 실행 에러n");
exit(1);
}
while(1){
if(-1 == listen(server_socket, 5)){
printf( "대기상태 모드 설정 실패n");
exit(1);
}
client_addr_size = sizeof( client_addr);
client_socket = accept( server_socket, (struct sockaddr*)&client_addr, &client_addr_size);
if (-1 == client_socket){
printf( "클라이언트 연결 수락 실패n");
exit(1);
}
read (client_socket, buff_rcv, BUFF_SIZE);
printf("receive: %s\n", buff_rcv);
sprintf(buff_snd, "%ld : %s", strlen(buff_rcv), buff_rcv);
write(client_socket, buff_snd, strlen(buff_snd)+1); // +1: NULL까지 포함해서 전송
close(client_socket);
}
}



traceroute라는 툴이 있음
어떤 ip까지 어떻게 routing되어 전달되는지 확인하는 것
ex) traceroute www.googel.com
시간 문제로 인해 초스피드로 진도 나감
------------------------------------------------------------------------------------------------------------------------
인터럽트와 후반부(BH) 처리
외부기기로 부터 / CPU 내부에서 발생할 수 있음
수업에선 enp0s3 (외부기기), Local timer에 대해 설명함
$ cat /proc/interrupts

CPU 밑에 적혀 있는 내용은 해당 interrupt가 각 CPU에서 몇번 실행되었는가를 나타냄
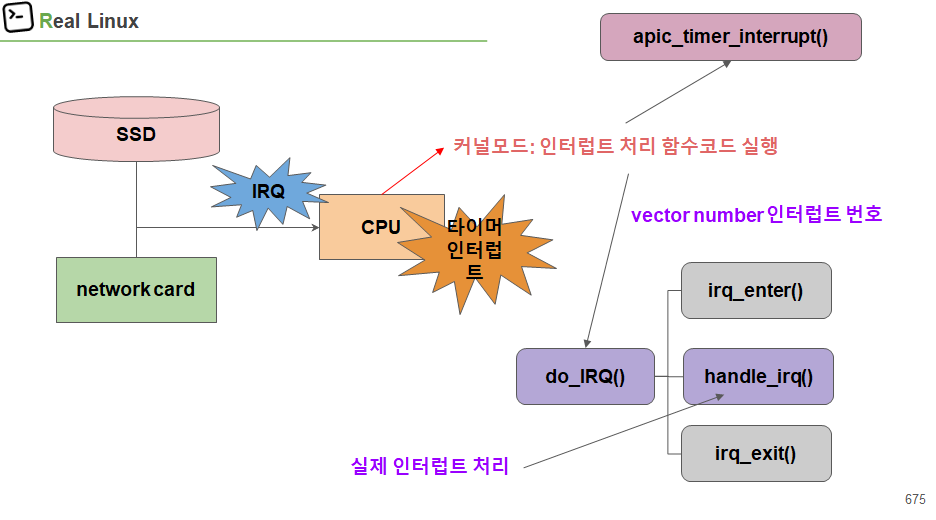
handle_irq()를 통해 처리 된다.
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > events/irq/irq_handler_entry/enable
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > events/irq_vectors/local_timer_entry/enable
root@ubuntu:/sys/kernel/debug/tracing# echo > trace
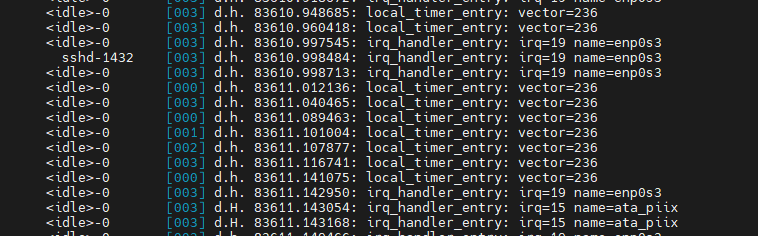
------------------------------------------------------------------------------------------------------------------------
IRQ 인터럽트 처리 과정 소스 코드 탐색
$ vim ${linux}/arch/x86/entry/entry_64.S


크게 3가지로 나눠짐
1) irq_enter()
2) handle_riq()
3) irq_end()
entering_irq() / exiting_irq() -> irq의 시작과 끝을 알림
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > events/irq/irq_handler_entry/enable
root@ubuntu:/sys/kernel/debug/tracing# echo do_IRQ > set_graph_function
root@ubuntu:/sys/kernel/debug/tracing# echo function_graph > current_tracer
root@ubuntu:/sys/kernel/debug/tracing# cat trace
CPU를 지정해서 TRACING 하는 방법
root@ubuntu:/sys/kernel/debug/tracing# cat per_cpu/cpu3/trace
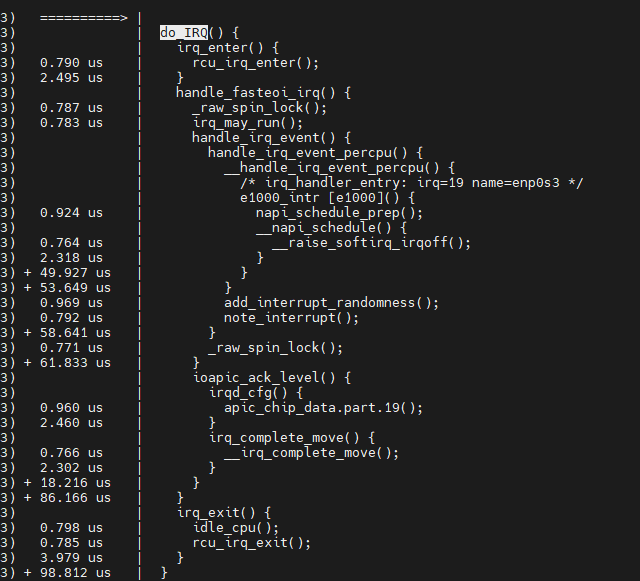
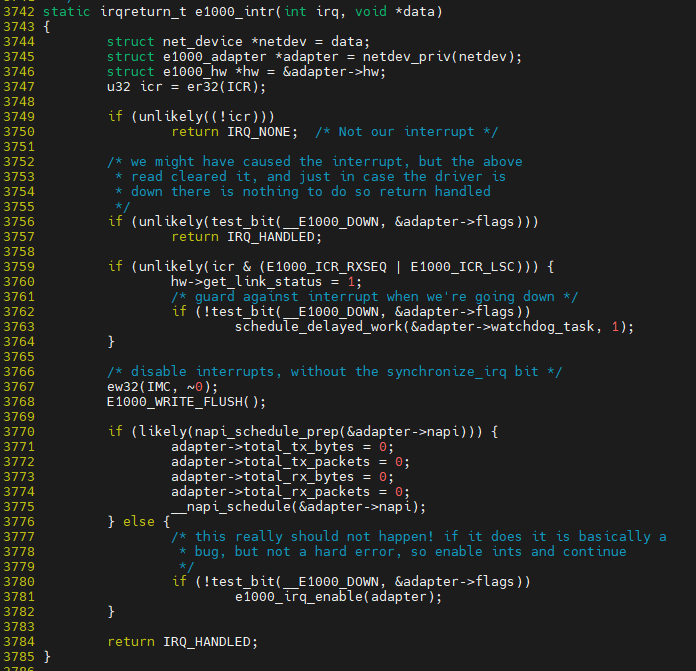
e1000_intr이 결국 enp0에 대한 irq handler이다
$ vim ${linux}/drivers/net/ethernet/intel/e1000/e1000_main.c.
$ vim ${linux}/arch/x86/entry/entry_64.S
내에서 LOCAL timer에 대한 IRQ hnadler 확인


# echo 1 > events/irq_vectors/local_timer_entry/enable
# echo smp_apic_timer > set_graph_function
# echo smp_apic_timer_interrupt > set_graph_function
# echo function_graph > current_tracer
# cat trace

------------------------------------------------------------------------------------------------------------------------
softirq 인터럽트 후반부 BH(Bottom Half) 처리
지금 당장 처리 하지 않아도 되는 함수들을 조금 미뤄서 진행 한다. (후반부로 미뤄서 한다)
sortirq 같은 경우에는 어떤 task가 실행해주게 되냐면은

core개수만큼 존재하며, 평소에는 sleep으로 있다가 처리해야 할 것이 생기면 wake-up으로 깨어나게 됨
전반부 처리되어야 하는 것은 hard irq라 하며 handle_irq() 부분
후반부 작업으로 미룰 수 있는 것은 __do_softirq()임
미뤄진 작업은 커널 스레드 ksoftirqd를 통해 나중에 실행 됨
softirq로 처리될 수 있는 함수들은 부팅시점에 미리 지정해 놓는다. 아래 10개이다.
$ cat /proc/softirqs

동적으로 특정 함수들을 미루거나 다양한 함수들을 기준으로 이 함수를 미룰수 있거나 그러진 못한다.
부팅 시점에 나중에 처리할 함수를 미리 정해놓았다.
tasklet와 workqueue는 queue를 통해 조금 더 유연하게 작업을 미룰 수 있다.

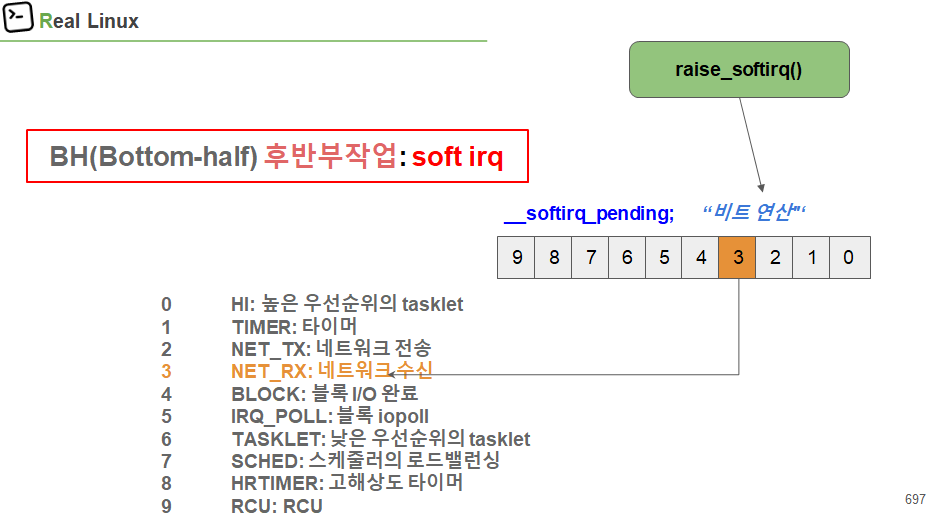
TH 부분이 끝난 뒤 irq_exit()부분에서 softirq가 연속적으로 실행되기도 한다. buysy하지 않는 이상.
이때, TH 부분의 __raise_softirq() 부분이 __softirq_pending 변수의 bit 부분에 대해 set 한다. 이것을 통해 추후에 이 부분에 대해 irq handle을 해달라고 요청하는 것이다. 이것이 set되어 있기 때문에 irq_exit 이후에 연속적으로 할수도 있는 것이다.
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > events/irq/softirq_raise/enable
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > options/stacktrace
root@ubuntu:/sys/kernel/debug/tracing# cat trace | less
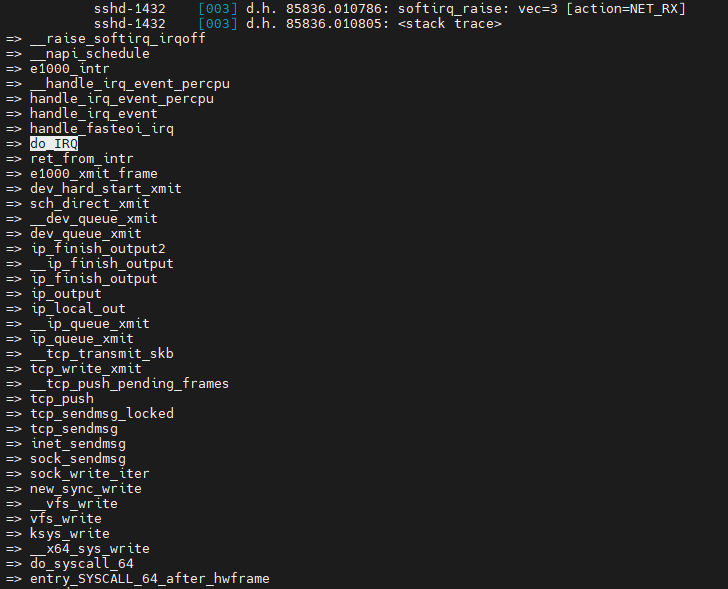
VEC=3에 대해 __raise_soft_irq를 통해 set
------------------------------------------------------------------------------------------------------------------------
softirq에 대한 코드 부분 확인
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > events/irq/softirq_raise/enable
root@ubuntu:/sys/kernel/debug/tracing# echo do_IRQ > set_graph_function
root@ubuntu:/sys/kernel/debug/tracing# echo function_graph > current_tracer
root@ubuntu:/sys/kernel/debug/tracing# cat trace | less
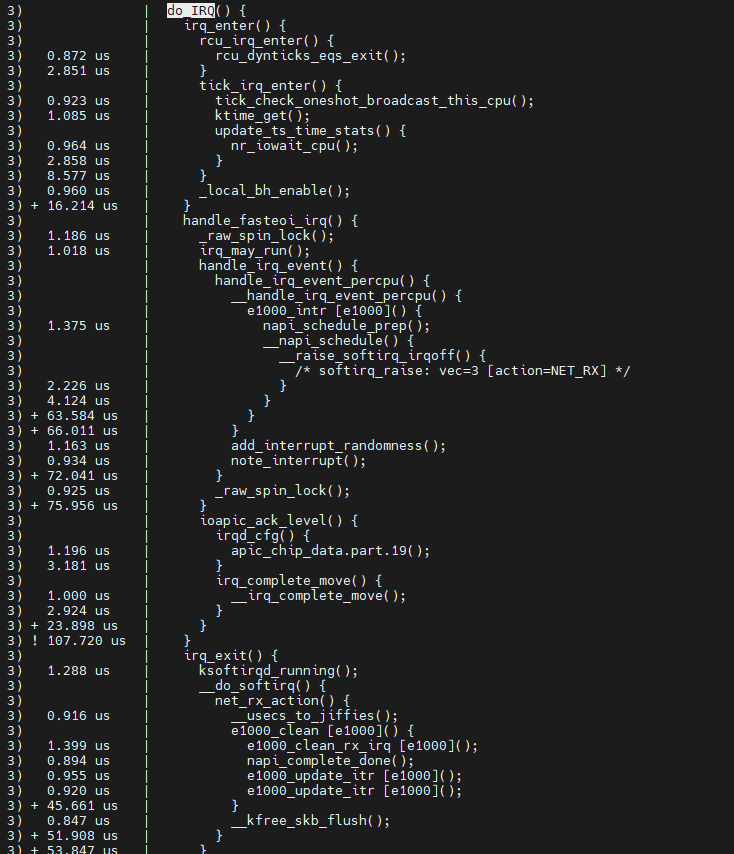
ksoftirqd에 의해 발생하는 것에 대해 tracing
echo ${pgrep ksoftirqd} > set_event_pid
echo 1 > events/irq/softirq_entry/enable
echo 1 > options/stacktrace
cat trace | less
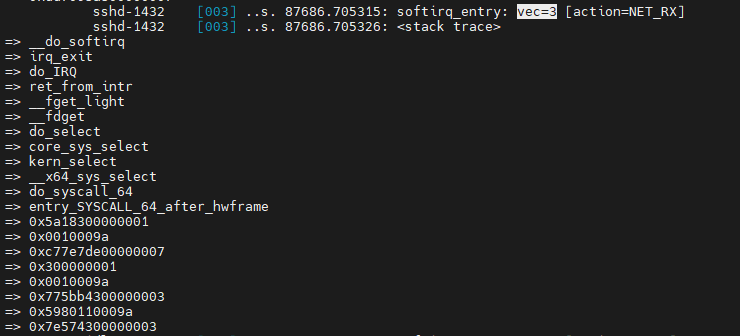
$ vim ${linux}/kernel/softirq.c

------------------------------------------------------------------------------------------------------------------------
다양한 후반부 작업 함수 추가 : tasklet
task 내부에서 처리하는 것임
고정적으로 특정 함수만 하는 것이 아니라 다양한 함수를 추가해 후반부 작업으로 할때 사용함


나중에 처리해줘라고 tasklet으로 후반부 작업 신청하는데, 이것을 누가 할지 말지 결정하냐면 이것은 schduler 함수에서 한다.
------------------------------------------------------------------------------------------------------------------------
workqueue란?
커널 함수 작업 미루는 방법
workqueue도 종류별로 여러가지가 존재 한다.
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > events/workqueue/workqueue_queue_work/enable
root@ubuntu:/sys/kernel/debug/tracing# echo 1 > options/stacktrace
root@ubuntu:/sys/kernel/debug/tracing# cat trace | less
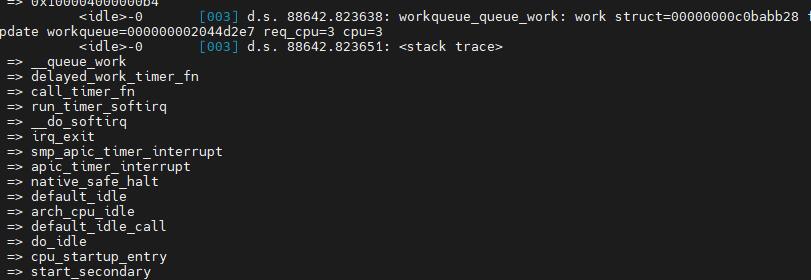
'Linux Kernel' 카테고리의 다른 글
| [운영체제] [리눅스 커널 5.0 동작과정 이해와 tracing 실습] 강의 목차 및 수업 계획서 (0) | 2021.10.08 |
|---|---|
| [운영체제] [리눅스 커널 5.0 동작과정 이해와 tracing 실습] 4일차 - 수업중 필기 (1) | 2021.10.08 |
| [운영체제] [리눅스 커널 5.0 동작과정 이해와 tracing 실습] 3일차 - Block layer (0) | 2021.10.08 |
| [운영체제] [리눅스 커널 5.0 동작과정 이해와 tracing 실습] 3일차 - file (0) | 2021.10.08 |
| [운영체제] [리눅스 커널 5.0 동작과정 이해와 tracing 실습] 3일차 - Write/Read/Open 처리 과정 이해 (Open) (0) | 2021.10.08 |