https://m.blog.naver.com/bitnang/70183421214
내용
1.파일시스템 소개
[파일시스템의 정의]
[파일시스템은 저장장치 내에서 데이터를 읽고 쓰기 위해 미리 정해진 약속] 이라고 볼 수 있다.
즉 미리 정해진 약속, 규약이라고 보면 될것으로 생각 된다. 네트워크에서는 프로토콜의 경우를 떠올려보자.
간단히 예를 들어 보도록 하자. RPG게임을 한다고 했을 때 게임을 진행하기 위해 게임을 진행하다가 세이브를(저장)을 하게 될 것이다. 세이브 파일에는 케릭터의 종류, 레벨, HP, MP, 현재위치, 돈 등이 기록되어야 불러올 때 이전에 진행했던 위치부터 게임이 진행 될 것이다.
이 때 필요한 데이터를 어떻게 저장할까?
[데이터 저장 규약의 예]

파일에 데이터를 저장하기 위한 방법의 예로서 총 6종류 데이터를 12Byte의 공간에 위치와 크기에 대한 약속을 정해서 저장한 것이다.
종류가 늘어나게 된다면 같은 파일 뒤에 위의 규약대로 이어서 저장을 하거나 아니면 다른 파일에 똑 같은 방식으로 저장을 하면 될 것이다.
파일 시스템 역시 위와 같이 저장할 데이터를 결정하고, 그 크기와 위치 등을 미리 약속한 뒤 운영체제 등에서 그대로 사용하면 된다.
물론 실제 파일시스템의 데이터 구조는 방대하고, 복잡하겠지만 결국 '미리 약속한 방법으로 저장하고 읽어 들이는 것'이다. 따라서 너무 어렵게 생각 하지 말고 진행하도록 하자.
[파일시스템 선택의 필요성]
수많은 파일 시스템 중 내가 사용하기 위한 용도에 맞는 파일시스템의 선택에 대해 알아보자.
파일시스템들의 특징이 서로 다른 것 처럼 각각의 용도에 따라 선택을 달라지게 하는 것이 좋다.
2.파일시스템 분류
1)일반적인 파일시스템
가장 일반적인 파일시스템은 디스크(플로피, 하드디스크)와 같은 저장장치에서 주로 사용된다. 앞으로 계속 자세하게 분석할 파일시스템들이지만 여기서 그 종류와 간략한 구조를 알아보자.
[FAT(File Allocation Table) 파일시스템]
- 마이크로소프트사의 빌게이츠가 만들었으며 전 세계적으로 가장 많이 사용되는 파일시스템
- 초기에 만들어졌으며 여러 번 발전을 거듭해 왔지만, 최초 제작 당시에는 고려하던 저장장치의 크기가 매우 작았으며 성능상 문제는 큰 이슈로 작용하지 않음.
- 매우 단순한 구조를 지니고 있으며 최근엔 대용량 저장을 위해 FAT16, FAT32 등이 만들어진 이후 윈도우 OS의 흥행과 더불어 지금도 널리 사용되고 있다.
- FAT파일시스템의 범용성은 휴대용 장치들과 PC와의 호환성을 높여주는 결과를 가졌으며, 이동식 저장장치들은 FAT파일시스템을 설치하기만 하면 별도의 설치과정 없이 엔드유져(End User)들의 PC에서 간편하게 읽어 들일 수 있게 만들어 짐.
- 파일시스템에서 사용되는 부가 기능은 적고, 제약사항들은 많은 단점이 있으나 그만큼 가볍고 심플하다.
- 단점으로는 연결 리스트를 사용한 자료구조로 인해 검색시간이 오래 걸리고, 파일 데이터 블록들이 여기저기 흩어지는 단편화 현상이 심해져 한파일의 데이터를 읽어 들이는 데도 디스크 헤드가 여러 번 이동하게 만들어짐.
- 디스크 조각 모음 등의 부가적인 프로그램이 등장하였지만 근본적인 해결책이 되지 않아 서버 시스템 등에서 사용되기에는 여러 가지 부족함이 많은 파일시스템이기 때문에 이후 여러 파일시스템들이 이를 개선하기 위해 등장하게 됨.
[HPFS(High Performance FileSystem)]
- IBM의 OS/2 1.2 부터 사용된 파일시스템이며 NTFS가 나오기 까지 많은 영향을 준 파일시스템.
- 제작 당시부터 대용량 디스크에 적합한 구조를 지니고 있으며, 효율적인 캐싱과 FAT파일시스템에 비해 파일 손실과 단편화가 적고, 서버 시스템에 사용할 수 있도록 여러 가지 보안 기능 등에 대한 요구를 충족시켜 줄 수 있는 파일 시스템이다.
- 대용량 저장 장치를 타켓으로 하였기 때문에 200MB 미만의 저장장치에서는 성능저하를 가져올 수 있는 단점이 있으며, 섹터 크기가 512Byte로 고정되었기 때문에 기본 데이터 I/O 단위를 변경할 수 없다.
- OS/2가 윈도우 NT와의 경쟁에 밀려 흥행에 실패하였고, 윈도우 NT 4.0부터는 HPFS를 지원하지 않아 호환이 불가능하여 우수한 성능 및 발전 가능성에도 불구하고 비운의 파일시스템이 됨.
[NTFS(New Technology FileSystem)]
- 마이크로소프트사의 서버급 운영체제인 Windows NT에 사용되는 파일시스템.
- 윈도우 NT 및 2000 이상의 OS에서 대표적인 파일시스템으로 자리 잡아 서버 시스템은 물론 일반 PC에서도 널리 사용되고 있다.
- NTFS는 대용량 저장장치를 겨냥해서 제작 되었으며, 높은 안정성과 부가기능 지원하고, FAT와 HPFS에 있던 여러 제약 사항들을 크게 개선한 파일 시스템이다.
- 제작사인 마이크로소프트사에서 전체 스팩을 공개하지 않아 완벽한 분석이 이루어지지 않았으며, 이로 인해 리눅스 등의 다른 OS에서 NTFS를 지원 한다고 해도 미흡한 부분이 있을 수밖에 없다.
[UFS(Unix FileSystem)]
- 유닉스의 대표적인 파일시스템으로 현재까지 쓰이는 대부분의 유닉스에서 사용되는 파일시스템의 근간이 됨.
- BSD계열(FreeBSD, NetBSD, OpenBSD 등)은 물론 HP-UX, Apple OS X, Sun Solaris에 이르기 까지 많은 유닉스 계열의 OS들이 UFS를 각각의 OS에 맞게 변형해서 사용하고 있다.
- UFS는 빠른 속도와 높은 안정성을 목표로 만들어짐.
- 저장장치를 그룹화하여 관련된 데이터끼리는 최대한 가까운 위치에 자리할 수 있는 구조로 되어 있어 디스크 헤드의 이동이 비교적 적고, 중요한 데이터는 이런 그룹에 걸쳐 많은 백업을 저장하므로 만일의 사태에 대하여 보다 신뢰성을 높임.
- 미국 Berkeley 대학의 FFS(Fast FileSystem)에서 근간을 이루었으며, Bell 연구소에서 Unix Version7을 개발할 때부터 본격적으로 UFS라는 명칭을 사용하였다. UFS는 리눅스 파일 시스템인 Ext2 에 큰 영향을 미치게 된다.
[Ext2파일 시스템(Second Extended FileSystem)]
- 현재 리눅스의 기폰 파일시스템인 Ext3에서 저널링 기능을 뺀 파일 시스템으로서 UFS를 근간으로 하고 있다.
- UFS에서 유명무실한 구조들은 제거하고, 전체적인 구조를 보다 간략히 한 Ext2는 비교적 명료하고 간단하면서 UFS의 속도와 안정성을 고류 갖춘 파일 시스템이다.
- 현재까지도 리눅스 기본 파일시스템으로 자리잡고 있는 Ext3에서 그대로 사용 되고 있다.
2)플래시 파일 시스템
- 플래시 파일시스템(Flash FileSystem)의 특징은 플래시 메모리의 특성에 최적화되어 있다.
- 플래시 메모리는 블록(Block)구조로 되어 있는데 읽는 것은 블록과 관계없이 바이트 단위로 자유롭지만, 쓰거나 지우는 것은 언제나 블록 단위로 해야만 한다. 이런 블록의 크기는 꽤 큰 편이여서 보통 64~128kb까지 된다.
- 플래시 메모리의 특징은 블록에 쓰기를 할 수 있는 횟수에 제한이 있다. 보통 10,000~100,000번 정도를 수명으로 본다. 이 수명은 플래시 메모리의 수명이 아니라 블록의 수명이다.
- 만약 어떤 플래시 메모리에 블록이 10개고, Write 횟수가 100,000일 경우 이 플래시 메모리에 블록 하나에 충분히 들어갈 만한 크기의 작은 데이터 하나만 기록한다고 했을 때 이 경우 블록을 돌려가면서 데이터를 쓰게 되는데 그 플래시 메모리의 수명은 100,000번 X 10블록 = 1,000,000번이 될 것이다.
- 임베디드 시스템에 담긴 플래시 메모리의 구조에 호환성은 별로 중요하지 않기 때문에 자체적으로 필요한 구조의 플래시 파일 시스템을 구현하여 제품에 올릴 경우가 만을 것인데 이때 임베디드 리눅스를 사용하게 된다면 JFFS2나 YAFFS 파일시스템을 주로 이용하게 된다.
3) 네트워크 파일 시스템
- 네트워크 파일시스템(Network FileSystem)은 1984년 Sun Microsystems에서 원격에 위치한 파일시스템을 로컬 파일시스템처럼 이용할 수 있도록 개발한 프로토콜이다.
- 단순히 파일 공유 차원의 것이 아니라, NFS도 결국 파일 시스템임을 인지 해야 하기 때문에 원격 파일시스템이 마운트되면 마운트 지점이 아래 위치한 파일에 접근을 하는 경우 NFS가 파일시스템 레벨에서 시스템 콜을 받아 직접 네트워크 파일을 수신하여 로컬 영역에 파일을 쓰거나 직접 실행할 수 있도록 한다.
- NFS의 초기 버전에서는 UDP 통신만 가능 했으나 이후 TCP도 지원하며, 파일 크기를 64bit까지 지원하여 4GB가 넘는 파일도 NFS로 이용 가능 하다.
4) 가상 파일 시스템
- OS 차원에서 가상 파일시스템(Virtual FileSystem)이라는 상위 레벨의 파일시스템 인터페이스가 존재하기 때문에 응용프로그램에서는 아무 구분 없이 OS 의 시스템 콜을 호출하면 커널은 미리 등록되어 있는 파일시스템 함수를 호출하여 그 종류에 상관없이 같은 결과를 볼 수 있다.
- 만약 가상 파일시스템이 없다면 일단 OS를 설치하고 나면 다른 파일시스템이 설치된 파티션을 인식할 수 없을 뿐만 아니라 다른 파일시스템의 인식을 위해서 별도로 컴파일 된 파일시스템 모듈을 덮어씌워야 할 것이다.
[가상 파일 시스템의 레이어구조]

- 가상 파일 시스템은 로컬 영역이나 원격 영역의 파일시스템을 실제로 제어하지 않기 때문에 OS 부팅 시에 시용 가능한 파일시스템 함수를 가상 파일시스템 쪽으로 등록해 주어야 한다. 일반적으로 하드디스크에서 사용하는 파일시스템뿐 만 아니라 CD-ROM 파일시스템과 네트워크 파일시스템 등 기본적으로 등록하는 파일시스템이 여러 가지 있다.
- 가상 파일시스템의 아이디어가 최초 적용된 OS는 1986 년 Sun Microsystems 의 SunOS 2.0 이다. 당시 SunOS 에서 로컬 영역의 UFS와 Remote 영역의 NFS를 통시에 지원하면서 그 개념이 도입되었고, 이후 대부분의 유닉스 계열의 OS들이 가상파일시스템을 지원하였다.
3. 파일시스템 요소들
1)기본요소
- 파일시스템은 커널 또는 응용프로그램에서 저장하고자 하는 데이터를 저장장치에 기록하기 위한 방법을 제시하므로 이에 필요한 저장장치 및 논리적 요소들을 알아볼 필요가 있다.
[클러스터]
- OS가 파일시스템 생성 시 저장장치의 크기를 고려하여 클러스터의 크기를 조절한다.
- 저장장치의 크기 및 사용 용도에 따라서 달라져야 한다.
- OS에 의해 데이터를 읽고 쓰는 과정에서 파일시스템은 미리 정해져 있는 클러스터의 크기를 기본단위로 하여 읽고 쓰는 과정에서 파일시스템은 미리 정해져 있는 클러스터의 크기를 기본단위로 하여 입출력을 하게 된다.
- 클러스터의 크기가 4096Byte라면 1Byte를 읽더라도 4096Byte를 읽어야 한다. 단순히 읽는 거라면 문제가 되지 않지만 쓰는 경우에는 문제가 될 수 있다.
- 클러스터 사용영역
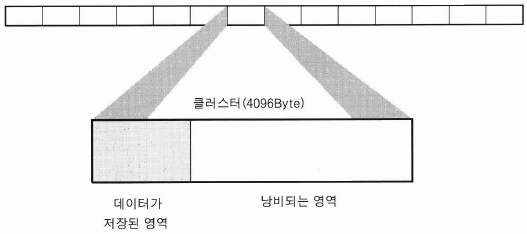
- 위 그림처럼 크기가 작은 파일을 저장할 경우 낭비되는 영역이 생기는데 이 부분의 공간은 사용이 불가능 해진다.
- 위처럼 낭비되는 공간이 있음에도 클러스터의 크기를 정하는 이유는 성능적인 측면 때문에 있다. PC사용시 처리속도에 있어 가장 큰 비용을 요구하는 작업은 디스크 입출력이다.
- 만약 10KB 파일을 읽을 경우 클러스터가 1KB라면 10번 I/O가 발생해야 하지만, 클러스터 크기가 4KB라면 3번의 I/O로 읽을 수 있을 것이다. 이 경우 2KB가량이 낭비되지만 요즘같이 대용량 하드라면 무시할 수 있을만한 정도이다.
- 파일시스템 역량과 저장장치 크기에 따라 클러스터의 크기가 저장장치 사용에 중요한 요소가 될 수 있다. 예를 들어 FAT16과 같이 파일시스템 주소 지정 방식에 16Bit를 사용하는 상황이라면 클러스터의 크기에 따라 최대 사용할 수 있는 저장장치의 공간이 차이를 보일 수 있다.
- 클러스터의 크기가 1KB라면 저장장치의 크기는 65,536(216) X 1,024(1KB) = 64MB
- 클러스터의 크기가 4KB라면 저장장치의 크기는 65,536(216) X 4,096(4KB) = 256MB 가 될 것이다.
- 32Bit, 48Bit, 64Bit 등 다양하게 사용되지만, 저장장치의 크기가 작고 가격이 비싸던 시절에는 상황에 따라 충분히 문제가 될 수 있다.
- 일반적으로 클러스터의 크기는 디스크를 포맷할 경우나 파일시스템을 생성하는 시점에 지정할 수 있으며, 최근의 대용량 하드에서는 주로 4KB의 크기가 기본으로 지정되어 있다. 플로피의 경우 기본 1KB로 지정되어 있다.
[파일]
- 파일시스템이란 결국 파일을 기록하기 위한 것이므로 파일을 이루는 구조와 그것을 관리할 수 있는 추가적인 방법을 제시하는 것이다.
- 파일은 속성을 기록하는 메타 데이터 영역, 실제 데이터를 기록하는 데이터 영역으로 나눌 수 있다.
- 메타데이터는 파일시스템에서 파일을 관리할 수 있는 정보 자체를 말하며 파일의 속성을 물론 실제 데이터를 기록한 위치를 찾아가기 위한 정보를 포함하며, 파일 시스템들은 이런 정보들을 어딘가에 저장해두고 OS가 정보 요청 시 해당 파일을 찾아서 정보를 조합하여 넘겨주면 사용자가 파일이라고 부르는 정보가 되는 것이다.
- 파일 정보 요청 프로세스
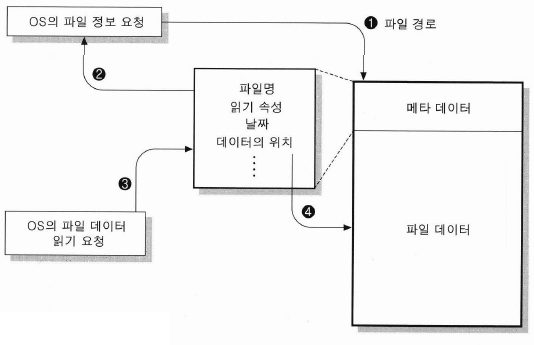
- 파일 데이터는 클러스터 단위로 읽고 쓸 수 있으며, 단 1Byte라도 사용한다면 1개의 클러스터 영역이 사용된다. 최근 하나의 클러스터에 여러 파일 정보를 담을 수 있는 연구가 진행중이며, 현재 스펙상 이것이 가능한 파일시스템도 있지만, 실제 사용되는 경우는 없다.
- 모든 파일시스템은 파일 정보를 관리하는 자료구조를 가지며, 이 자료구조에 의해 파일시스템의 성능에 큰 영향을 끼치게 된다.
- FAT의 경우 연결리스트, NTFS는 B-Tree를 사용하며, 두 알고리즘의 특성과 마찬가지로 검색기능에 있어 NTFS가 FAT에 비해 효율이 좋은 것처럼 여러 가지 차이를 보인다.
[디렉토리]
- 파일들을 계층화하고 그룹화 할 수 있는 개념으로, 상, 하위 개념의 디렉토리와 파일들은 관리하는데 있어 많은 이점을 제공하며, 때로는 이런 개념을 뛰어넘기 위한 링크(Link) 등의 방법을 제공하는 파일 시스템도 있다.
- 파일과 디렉토리에 대한 속성 정보를 따로 만들어 놓고 이를 통해 파일과 디렉토리를 구분하여 관리하지만, 실제 안을 들여다 보면 결국 비슷하다.
- 파일의 경우 데이터 영역에 있어 파일 정보에서 그것의 위치를 가리키며, 디렉토리의 경우도 데이터 영역이 존재하는데 이 영역에는 하위 존재하는 디렉토리 및 파일 리스트 들이 있다.
- 가장 상위 디렉토리의 경우 파일시스템에 따라서 관리하는 방법이 다르므로 해당 파일 시스템의 분석을 살펴보도록 해야한다.
2)부가요소
[소유권]
- 개인용 컴퓨터와 서버용 컴퓨터에서 사용하는 파일시스템간의 두드러진 차이점 중의 하나는 파일마다 그룹과 소유권을 따로 관리할 수 있다는 점이다.
- 한대의 컴퓨터에 여러 명의 사용자가 접근하는 경우 각 사용자들의 파일에 대한 접근 권한을 따로 관리할 필요가 있으며 시스템 관리자의 입장에서도 사용자들이 아무 제제 없이 시스템 파일에 접근하는 것을 막아야 한다.
- FAT파일시스템에서는 소유권을 관리할 수 없기 때문에 OS차원에서 제한을 두는 것은 한계가 있다.(Win 98의 경우 사용자 계정을 달리 로그인할 수 있지만, 정작 그들간의 접근할 수 있는 파일에는 제한이 없다.)
- NFTS나 EXT2를 비롯한 서버급 파일시스템은 모든 파일에 사용자 그룹과 소유권한을 부여할 수 있어 사용자가 시스템 파일에 허가 없이 접근하는 것을 막을 수 있다.
[동기화]
- 현재 모든 OS들은 멀티태스킹(Multi-Tasking) 기능을 지원하여, 하나의 CPU에서도 여러 프로그램이 동시에 실행되는 것처럼 동작한다.
- 이때 주의할 점이 동기화 작업이다. 하나의 파일에 여러 프로세스가 동시에 접근해서 작업을 하는 경우 파일에 락(Lock)을 걸어주고, 적절한 시점에 해제하는 동기화가 진행되어야 하는데, 파일시스템을 제작하면서 동기화만큼 손이 많이 가는 작업이 드물다.
- 여러 가지 상황에 따른 고민과 여러 가지 상황의 문제가 생길 수 있기 때문에 많은 시간이 소요된다.
(만약 A라는 파일에 삭제 명령을 하고 동시에 A라는 파일을 읽기 명령이 진행 되었을 경우 A라는 파일이 락이 걸려있지 않다면 삭제되고, 읽을때 잘못된 포인터 접근하여 세그먼테이션 오류를 발생 시킬 수 있다.)
- 최근에 사용되는 파일시스템들은 대부분 파일에 락을 걸 수 있도록 스펙이 정의되어 있는데 락에는 그 유형과 적용 해야하는 위치가 다양하기 때문에 파일시스템을 제작할 경우 각별히 신경써서 구현해야 한다.
[일관성(Consistency) 체크와 저널링]
- 예기치 못한 상황에서 시스템이 멈추거나 정전이 일어날 경우 문제가 발생하는데 파일을 쓰고 있었다거나, 중요 업데이트를 하고 있을 경우 실제 파일이 없는데 있는 것처럼 표시되어 데이터가 잘 못될 수 있는 등 일관성이 깨지게 된다.
- 가장 우선적으로 파일시스템 구현 시 이런 상황을 대비 해야하며, 파일을 쓸 때 메타데이터와 파일 데이터를 쓰는 순서를 시스템 Crash 상황을 고려 해야한다.
- 메타데이터를 먼저 쓰고, 파일 데이터를 쓰게 될 경우 파일 데이터 쓰는 도중 시스템 중단되면 파일이 있는 것처럼 보이겠지만 실제론 없을 것이다. 그러나 반대로 파일 데이터를 먼저 쓰고 메타데이터를 쓸 경우 시스템이 중단이 되어도 메타데이터가 나중에 쓰여지기 때문에 파일리스트에 없을 것이며, 해당 파일데이터가 쓰여진 곳은 어차피 빈 영역이고, 나중에 다른 데이터가 쓰여지게 될 것이다.
- 파일시스템 일관성 문제가 발생했을 경우 별도의 유틸리티 프로그램이 요구된다. chkdsk.exe(FAT, NTFS), e2fsck(Ext2) 등이 있다.
- 이런 프로그램은 파일시스템 내에 존재하는 모든 메타 데이터를 검색하여 문제가 있는 부분은 수정한다. 그러나 요즘 같은 경우 용량이 크기 때문에 시간이 많이 걸릴 수도 있다. 이런 상황을 위해 대두된 것이 저널링 기능이다.
- 저널링은 데이터베이스에서 일관성 체크를 위해 사용되는 방법을 파일시스템에 적용한 것으로 파일시스템 업데이트 시에 로그를 기록하고, 문제가 생길 경우 해당 로그를 참조하여 업데이트를 취소할 수 있고, 파일시스템에 적용완료(commit)할 수 있다.
- 저널링 기능의 큰 장점은 업데이트 로그를 기록하고 있기 때문에 일관성 체크를 위한 파일시스템의 전 영역을 검색하지 않아도 되며, 해당 로그만 찾아가서 작업을 수행하면 된다. 따라서 시간이 많이 단축될 것이다.
[보안]
- 파일의 소유 권한과 실행 권한 등을 다루는 방법.(OS등을 통해 파일시스템에 접근하는 상황에 해당될뿐 물리적으로 접근시 데이터가 들어남)
- 파일시스템 암호화 기법으로 암호화를 적용하는 계층은 가상 파일시스템과 파일시스템 자체에서 할 수 있다. 또는 메타 데이터만을 암호화 하는 경우와 파일 영역까지 압축을 통한 암호화를 진행하기도 하며, 디렉토리 및 파일 등을 선택해서 적용할 수 있다.
4. 저장장치
[저장장치 소개]
- 저장장치는 주기억 장치인 메모리와 구분을 위해 보조기억장치라고 불리며, 여기서는 보조기억장치대신 저장장치라는 용어로 진행한다.
- 장치간의 속도와 용량 관계
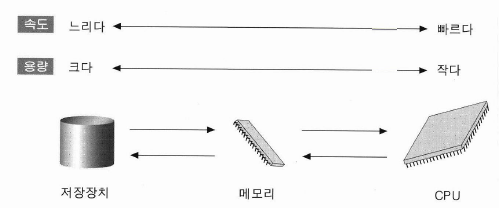
- 컴퓨터는 전원이 나갈 경우 기억하던 데이터를 잃어버리는데 이를 대비하여 저장장치(보조기억장치)에 저장해 놓는다.
- 주기억장치인 메모리의 경우 저장장치에 비해 값이 비싸기 때문에 상대적으로 작은 양에 데이터들을 담고, 해당 데이터의 처리가 끝나고 다른 데이터를 처리할 경우 저장장치로부터 읽어 들이는 방법을 사용한다.
- CPU입장에서 저장장치들은 너무 느리기 때문에 속도가 상대적으로 빠른 메모리에 적재한 후 CPU가 처리하는 식으로 진행이 된다.
- 저장장치로부터 한 번 데이터를 읽어서 메모리에 올렸다면 최대한 저장장치를 접근을 하지 않는 것이 좋으며, CPU는 메모리에 올린 데이터를 최대한 적게 접근하여 데이터들을 처리하는 것이 좋다.
[저장장치 분류]
- 시간이 지나면서 저장장치의 종류와 형태는 매우 다양해졌다.
- 저장장치(Storage Device)를 분류하는 방식에는 여러 방법이 있지만, 데이터를 저장하는 방식에 따라 분류를 해보자.
1)자기(Magnetic) 방식
- 자기적인 특성을 이용하여 데이터를 저장하는 방식으로 종이를 이용한 천공카드(Punch card) 다음으로 오래된 기술이다. 천공카드의 경우 저장장치 무대에서 사라졌지만, 자기 저장 방식은 구조와 기술의 진보를 통해 다양한 형태로 계속 진화하여 지금까지도 주요 저장 방식으로 사용되고 있다.
- 종류로는 자기테이프, 자기드럼, 플로피, 하드디스크 등이 있다.
- 가장 대중적인 매체는 하드디스크로 대부분의 파일시스템들이 하드디스크에 적용하기 위해 개발되었을 정도이다.
- 저장 방식의 특성상 자기장에 약한 단점이 있다.
2) 전기(Electronic) 방식
- 전기적인 특성을 이용하는 저장장치들은 특성상 전부 반도체의 범주에 속한다.
- 가격이 비싸고 저장용량도 작아서 주요 저장장치로 사용되지 않다가 최근 플래시 메모리의 비약적인 기술 발전으로 널리 사용되고 있다.
- 다음은 전기적인 특성을 이용하는 저장 장치이다.
|
매체 |
설명 |
|
PROM |
딱 한번 기록할 수 있는 ROM |
|
EPROM |
자외선으로 지운 후 기록 가능한 ROM |
|
EEPROM |
전기적 특성으로 지운 후 기록 가능한 ROM |
|
FLASH-ROM |
EEPROM보다 진보된 메모리 |
- 사실 PROM, EPROM, EEPROM과 같은 제품들은 저장장치(Storage Device)라기 보다는 메모리쪽에 가깝다. 형태가 IC와 같이 외부 인터페이스 없이 CPU와 연결이 가능하기 때문이다.
- 플래시 메모리의 경우 이런 분류를 모호하게 하는데 특성상 메모리에 가까운 제품이지만 활용도가 높아 이동용 저장장치에 주로 사용된다.
- 기술적인 특성상 생산 단가가 낮고, 집적도를 높일 수 있어 큰 용량이 가능하였다. 이를 토대로 여러가지 저장장치들이 판매되고 있는데 CF(Compact Flash) Card, Memory Stick, SD Card, USB Memory 등 다양한 제품이 모두 플래시 메모리를 응용한 것이다.
- 이런 저장장치들은 부피를 매우 줄일 수 있으며, 외부 충격에 강한 편이다.
- 플래시 메모리는 특성에 최적화된 파일시스템을 올리는 것이 좋은데 JFFS2나 YAFFS같은 파일 시스템이 플래시메모리에 최적화된 파일시스템이다.
- 이럴 경우 Windows와 호환을 포기해야 하는데 Windows와 호환이 주목적이라면 플래시메모리라고 할지라도 FAT를 구현하는 것이 좋다.
3)광학(Optical) 방식
- 레이저(Laser)를 이용하여 빛을 쏘았을 때 패인 곳과 그렇지 않은 곳에 빛의 반사율이 다른 점을 이용하여 데이터를 읽거나 쓰는 방식이다.
- 자기방식과 전기 방식의 중간쯤 되는 것으로 다른 방식보다 적은 비용이 들고, 흠집이 나지 않는다면 충격에 강하며, 물에 빠져도 잘 말리면 될 것이다.
- 광학 매체의 특성상 쓰는 속도가 느린 편이라 대량의 데이터를 손쉽게 움직이기에 무리가 있으며, 주로 Backup용으로 사용되는 경우가 많다. 그러나 쓰는 속도가 느리기 때문에 실시간으로 데이터를 읽고 쓰고 하는 용도로 쓰는 경우는 없을 것이다.
- ISO 0660과 같은 파일 시스템을 사용하고, CD-RW를 지원하는 UDF(Universal Disk Format)같은 파일 시스템도 있다.
5.하드디스크 분석
[하드디스크 소개]
- 컴퓨터가 데이터를 저장하는데 가장 일반적인 저장장치이다.
- 가장 많이 사용되는 만큼 파일시스템도 매우 다양하다.
[하드디스크의 주요 구성요소]
- 하드디스크 물리 구조에서 실린더, 트랙, 섹터를 주로 다루게 되는데 이는 디스크 읽는 단위로도 사용되기 때문에 알아둘 필요가 있다.
- [하드디스크의 구조]
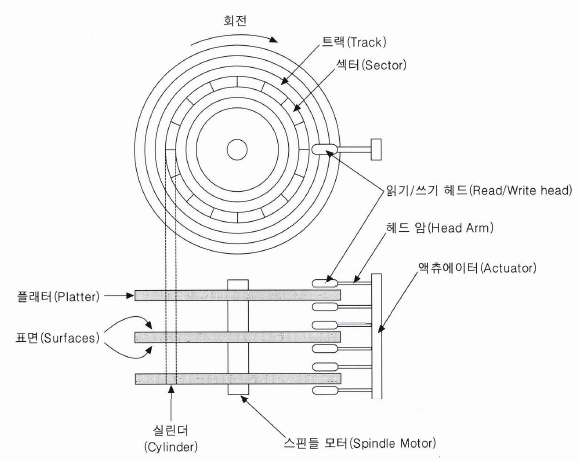
- 하드디스크의 경우 여러장의 플래터로 이루어져 있고, 표면은 트랙과 섹터로 나눠지게 된다.
- 플래터의 표면마다 헤더가 위아래로 있기 때문에 '플랙터 X2'가 될 것이다. 따라서 헤더의 개수와 표면의 개수가 같기 때문에 주로 헤드의 숫자만 언급하는 경우가 많다.
|
[트랙] |
디스크 중심으로 반지름이 같은 영역을 이어놓은 원을 보면 될 것이다. 반지름이 커질수록 디스크의 가장자리 영역에 데이터를 많이 보관할 수 있게 된다. |
|
[섹터] |
트랙을 자른 형태가 섹터가 될 것이다. 각 섹터는 571Byte의 공간은 차지한다. 이중 59Byte는 각 섹터에서 고유 번호등을 저장하며 나머지 512Byte가 사용자들의 데이터 저장에 사용되는 영역이다. 따라서 통상적으로 섹터의 크기는 512Byte라고 이야기 한다. 디스크에서는 섹터보다 적은 양의 데이터는 처리할 수 없기 때문에 데이터 기록의 가장 기본단위로 쓰여지며 이는 트랙과 함께 가장 중요한 단위이다. |
|
[실린더] |
하드디스크의 경우 플래터가 여러 장 겹칠 것인데 이 경우 같은 위치에 있는 트랙들을 합쳐서 실린더라고 한다. (예를 들어 4장의 플래터와 플래터 표면의 100개의 트랙이 있다면 100개의 실린더가 있을 것이고 각 실린더에는 8개의 트랙이 있을 것이다.) |
|
[헤드] |
데이터를 읽고 쓰기 위해 헤드암 가장 끝 부분에 있다. 각각의 플래터 표면에 하나씩 할당되어 있고, 각각의 헤드는 따로 움직이는 것이 아니라 헤드암에 의해 액츄에이터(Actuator)로 연결된다. 따라서 이 액츄에이터에 의해 각 플래터의 특정 위치를 찾아갈 수 있게 되며, 헤드가 각 플래터의 동일한 트랙을 돌며 움직이므로 실린더의 개념이 생겨난 것이다. |
[하드디스크 인터페이스]
- 하드디스크의 인터페이스로 사용하는 규격은 크게 2가지가 있는데 ATA또는 IDE라고 불리며, 다른 하나는 SCIS라고 불린다.
- 일반적으로 우리가 쓰는 것은 ATA이며 IDE와 혼용해서 이야기하는데 ATA라고 하는게 좋을 것이다.
- IDE(Integrated Drive Electronics)는 인터페이스를 만든 회사 이름이며, ATA(Advanced Technology Attachment)는 IDE에서 만든 이 인터페이스가 ANSI에 의해 표준으로 채택되고 나서 표준에 붙은 이름이다.
- ATA는 HDD를 접근하기 위해 만들어진 표준이다. 이전에는 회사들이 각각 다른 인터페이스를 가져 호환이 되지 않았는데 이를 해결하기 위해 표준으로 채택하였다.
- ATA는 가격이 저렴하고 인터페이스 제어가 편리한 부분이 많아 대중적으로 사용하게 되었고, SCSI의 경우 ATA방식에 비해 빠르고 확장성이 좋지만 비싼편이다. ATA 방식이 SCSI에 비해 저렴한 이유는 외부 컨트롤러를 따로 두지 않아도 되고, 인터페이싱을 하는 프로토콜이 SCSI의 프로토콜보다 단순하기 때문이다.
- ATA의 단점은 SCSI에 비해 CPU 점유율이 높다는 건데 DMA를 쓰게 되면 이문제도 많이 해결 하게 된다.
- PIO(Programmed I/O) 모드를 쓴다면 CPU점유율이 높은 편이다.
- ATA버전에 대한 용약이다.
|
버전 |
설명 |
|
ATA-1 |
최초의 규격 PIO 0, 1, 2 지원, swDMA 0, 1, 2 지원, mwDMA 0 지원 |
|
ATA-2 |
LBA 모 I 지원. PIO 3, 4 및 mwDMA 1, 2 추가 |
|
ATA-3 |
S.M .A.R.T 기능추가 |
|
ATAPI-4 |
ATAPI 규격과 통합 UDMA 0 1. 2. 3 추가 |
|
ATAPI -5 |
UDMA4(Ultra DMA 66) 추가 |
|
ATAPI -6 |
UDMA5(Ultra DMA 100) 추가 |
|
ATAPI -7 |
UDMA6(Ultra DMA 133) 추가 S-ATA 규격 포함 |
ATAPI-8 버전은 S-ATA에 관련된 기술로 생략 하도록 한다.
PIO : Programmed Input/Output 모드
swDMA(single word DMA) : 섹터를 한 번에 1개 밖에 전송하지 못하는 모드
mwDMA(multi word DMA) : 섹터를 한번에 여러 개씩 전송할 수 있는 모드
S.M.A.R.T : 보안과 하드디스크 자가 검증에 관련된 기술
ATAPI(Advanced Technology Attachment Packet Interface) : CD-ROM과 같은 장치를 연결 할 수 있음.
UDMA(Ultra DMA) : 특수한 UDMA 컨트롤러를 통해 더욱 빠른 속도로 전송하는 모드
S-ATA(Serial ATA) : Serial로 동작하는 새로운 인터페이스 방식
전송모드 속도
|
전송모드 |
사이를 타임(ns) |
최대 전송 속도(MB/Sec) |
|
PIO 0 |
600ns |
3.3MB |
|
PIO 1 |
383ns |
5.2MB |
|
PIO 2 |
240ns |
8.3MB |
|
PIO 3 |
180ns |
11.1MB |
|
PIO 4 |
120ns |
16.7MB |
|
mwDMA 0 |
480ns |
4.2MB |
|
mwDMA 1 |
150ns |
13.3MB |
|
mwDMA 2 |
120ns |
16.7MB |
|
UDMA 0 |
240ns |
16.7MB |
|
UDMA 1 |
160ns |
25MB |
|
UDMA 2 |
120ns |
33.3MB |
|
UDMA 3 |
90ns |
44.4MB |
|
UDMA4 |
60ns |
66.7MB |
|
UDMA 5 |
40ns |
100MB |
|
UDMA 6 |
30ns |
133.3MB |
- 소개한 모드는 전부 Parallel ATA로도 가능한 모드이며, S-ATA를 사용하면 더욱 빠르게 전송할 수 있다. 하지만 임베디드 장비에서 하드디스크를 사용하는 경우에는 일반적으로 mwDMA 모드나 PIO 모드를 기장 많이 시용하게 된다. UDMA 모드가 빠르기는 하지만 전용 UDMA 컨트롤러가 없으면 사용할 수 없기 때문이다.
- 위 표에서 설명한 모드들은 하드디스크의 물리적인 속도를 의미하는 것이 아니라 하드디스크와 CPU간의 인터페이스 속도를 의미한다. 즉, CPU와 하드디스크간의 인터페이스 속도가 아무리 빨라져도 실제로 하드디스크에 데이터가 기록되는 시간이 길어지면 별로 의미가 없다.
- 하드디스크는 내부에 원형의 플래터가 있고 이것이 보통 5400rpm에서 7200rpm으로 회전하며, 암(Arm) 끝에 달린 헤드가 플래터 위에서 왔다 갔다 하면서 데이터를 쓰거나 읽게 된다. 이렇게 헤드가 움직이면서 플래터에 접근 및 쓰기를 하는 속도는 그다지 빠르지 않다. 아무리 인터페이스 속도가 133MB /sec쩨 올라간다고 해도 내부에서 하드디스크는 속도가 받쳐주지 못하면 병목현상 때문에 성능이 많이 좋아지지 않는다.
- 때문에 5400rpm에UDMA -6보다는 7200rpm 에 UDMA-5가 더 성능이 좋을 수도 있다.
- 이러한 문제를 해결하기 위해 하드디스크 내부에 캐시 ιache)의 용량을 높이는 방법을 시용한다. 그러면 성능이 많이 향상된다.
[ATA 레지스터]
- ATA 레지스터들은 같은 어드레스의 레지스터라고 할지라도 그 레지스터를 읽느냐 쓰느냐에 따라 기능이 달라진다. 이때 코딩할 때 실수를 저지를 수 있는데, 예를 들어 레지스터 중 데이터 레지스터에 특정한 값을 쓴 후 값이 제대로 들어갔는지 확인하기 위해 데이터 레지스터를 읽어보는 코드를 짠다면 제대로 작동하지 않을 것이다.
- [컨트롤 블록 어드레스]
|
어드레스 |
기능 |
|||||
|
/CSO |
/CS1 |
AO |
A1 |
A2 |
READ |
WRITE |
|
0 |
1 |
1 |
1 |
0 |
Alternated status |
Device Control |
|
0 |
1 |
1 |
1 |
1 |
Drive Address |
사용 안 함 |
- [커맨드 블록 레지스터]
|
어드레스 |
기능 |
|||||
|
/CSO |
/CS1 |
AO |
A1 |
A2 |
READ |
WRITE |
|
1 |
0 |
0 |
0 |
0 |
Data |
Data |
|
1 |
0 |
0 |
0 |
1 |
Error |
Feature |
|
1 |
0 |
0 |
1 |
0 |
Sector Count |
Sector Count |
|
1 |
0 |
0 |
1 |
1 |
Sector Number(LBA bit 0-7) |
Sector Number(LBA bit 0-7) |
|
1 |
0 |
1 |
0 |
0 |
Cylinder Low(LBA bit 8-15) |
Cylinder Low(LBA bit 8-15) |
|
1 |
0 |
1 |
0 |
1 |
Cylinder High(LBA bit 16-23) |
Cylinder High(LBA bit 16-23) |
|
1 |
0 |
1 |
1 |
0 |
Drive/Head(LBA bit 24-27) |
Drive/Head(LBA bit 24-27) |
|
1 |
0 |
1 |
1 |
1 |
Status |
Command |
- 주로 커맨드 블록 레지스터를 이용하여 하드디스크를 제어하게 되는데 몇몇 레지스터들을 'Sector Number(LBA bit 0-7)' 부분은 이것은 CHS방식이냐 LBA방식이냐 따라서 같은 레지스터를 다르게 사용하기 때문이다.
- CHS 모드를 사용한다면 그 레지스터는 Sector Number를 적는 레지스터가 되고, LBA로 HDD를 동작시키면 LBA Address중 0~7bit를 적는 레지스터가 된다. 레지스터들과 커맨드의 자세한 내용은 www.t13.org에 기술문서를 참고하도록 하자.
[CHS Address와 LBA Address]
CHS모드
- CHS모드는 각각 실린더(Cylinder), 헤드(Head), 섹터(Sector)를 나타내며 여기서 말하는 실린더는 트랙의 수직적 요소를 합한 것이 아닌 트랙 자체의 개념과 같다고 볼 수 있다. CHS로 나타내는 주소는 실린더와 헤드는 0부터, 섹터는 1부터 시작한다.
- 디스크의 주소는 물리적인 CHS주소로 나타내어지며, 초기의 하드디스크를 접근하는 방법도 CHS 주소를 사용한다.
LBA모드
- ROM BIOS를 이용한 CHS모드의 하드디스크의 접근은 현재 주로 사용되는 수십, 수백 GB의 하드디스크를 이용할 수 없다. 최대 8GB를 이용할 수 있을 것이지만, 이와 같은 제약을 극복하기 위해 물리적인 접근 방법이 아닌 논리적인 방식의 디스크 접근방법이 고안 되였다.
- LBA(Logical Block Area)는 CHS 모드와 같이 물리적인 특성에 따른 기본 단위를 따로 계산하는 것이 아니라 섹터들을 일렬로 죽 늘어놓은 것과 같은 논리적인 개념이다. 따라서 논리적인 번지는 내부적으로 물리적인 위치로 계산될 수 있기 때문에 주소 지정 시에 CHS모등인지 LBA모드인지만 구분하여 지정해주면 사용 가능 하며 트랙과 헤드를 구분 지어 나타낼 필요가 없기 때문에 통상적으로 228 까지 표현할 수 있다.
- 하나의 블록은 섹터와 같으므로 '512Byte X 228 = 128GB' 까지 사용할 수 있게 된다.
- 최근에는 이도 모자라 48bit LBA까지 지원하고 있다.
- LBA모드는 하드디스크의 물리적 정보를 따로 파악하여 넣어줄 필요가 없다. CHS모드의 경우 파티션 테이블을 구성하더라도 각각 물리적인 정보를 파악하여 값을 따로 구하여 넣어야 하지만, LBA 모드라면 단순히 사용하는 섹터의 숫자만 입력해주는 것으로 충분하다.
|
CHS |
LBA |
|
섹터의 주소를 지정할 때 Cylinder, Head, Sector의 주소를 정확히 적어 넣어서 지정하는 방식. 대용량화된 하드디스크에서는 쓰이지 않으며, 다만 ATA 레지스터 이름에서만 흔적을 찾을 수 있다. |
하드디스크를 각각 512Byte의 블록으로 나눈 다음 각각의 블록에 순차적으로 번호를 매겨 주소를 할당하는 방법. 120GB까지는 28bit 값을 가지고 제어 했으나 28bit 한계가 다다르게 되어 확장된 LBA 주소방식인 48bit LBA어드레스 방식을 사용 |
|
28bit로 처리할 수 있는 최대용량? 1block당 512byte를 담당. 268,435,455(228) X 512 = 137,438,952,960 약 127GB |
- LBA 방식에서 최소 단위는 1LBA(512Byte)이다. 하드디스크 Address의 0~511번째 바이트는 LBA의 0번에 해당된다.
하드디스크 Address의 512~1023번째 바이트는LBA의 1번에 해당된다.
만약 30번째 바이트를 0xFF라고 적고 싶을 때 30번째 1바이트만 0xFF로 바꾸고 싶다 할 지라도 우선 0번 LBA의 512Byte를 전부 다 읽고 30번째를 0xFF로 수정한 후 다시 LBA 0번에 덮어 써야 한다. 즉 1바이트를 읽어도 무조건 1LBA(512Byte) 단위로 행동 해야 한다.
5.저장장치 실습
Visual C++로 컴파일을 해보도록 하자.
아래 소스는 하나의 LBA를 읽어서 화면에 값을 보여주는 예제이다.
특히 HDD_read() 함수는 앞으로 모든 예제에 쓰일 것이다.
Visual Studio를 쓸때는 우클릭 – 관리자 권한으로 실행을 눌러서 켜자
그리고 프로젝트 우클릭 – 속성 – 일반탭의
문자집합 : 멀티바이트 문자 집합 사용으로 셋팅을 하도록 하자.

소스 중에서 필요한 부분만 입력했습니다.
진하게 한 부분은 살짝 수정한 부분 입니다.
#include <stdio.h>
#include <windows.h>
#include <stdlib.h>
#define U8 unsigned char
#define S8 char
#define U16 unsigned short
#define U32 unsigned int
#define U64 unsigned __int64
U32 HDD_read (U8 drv, U32 SecAddr, U32 blocks, U8* buf);
void HexDump (U8 *addr, U32 len);
int main(void) {
U8 dumpData[512];
HDD_read(0, 0, 1, dumpData);
HexDump( dumpData, 512);
return 0;
}
U32 HDD_read (U8 drv, U32 SecAddr, U32 blocks, U8* buf){
U32 ret;
U32 ldistanceLow, ldistanceHigh, dwpointer, bytestoread, numread;
char cur_drv[100];
HANDLE g_hDevice;
//WinAPI를 이용한 저장장치의 섹터 하나에 데이터를 읽는 함수
sprintf_s(cur_drv,sizeof(cur_drv),"\\\\.\\PhysicalDrive%d",(U32)drv);
g_hDevice=CreateFile(cur_drv, GENERIC_READ, FILE_SHARE_READ | FILE_SHARE_WRITE, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, 0);
if(g_hDevice==INVALID_HANDLE_VALUE) return 0;
ldistanceLow = SecAddr << 9;
ldistanceHigh = SecAddr >> (32 - 9);
dwpointer = SetFilePointer(g_hDevice, ldistanceLow, (long *)&ldistanceHigh, FILE_BEGIN);
if(dwpointer != 0xFFFFFFFF) {
bytestoread = blocks * 512;
ret = ReadFile(g_hDevice, buf, bytestoread, (unsigned long*)&numread, NULL);
if(ret) ret = 1;
else ret = 0;
}
CloseHandle(g_hDevice);
return ret;
}
void HexDump (U8 *addr, U32 len){ //버퍼에 들어 있는 값을 출력
U8 *s=addr, *endPtr=(U8*)((U32)addr+len);
U32 i, remainder=len%16;
printf("\n Offset Hex Value Ascii value\n");
// print out 16 byte blocks.
while (s+16<=endPtr){
// offset 출력.
printf("0x%08lx ", (long)(s-addr));
// 16 bytes 단위로 내용 출력.
for (i=0; i<16; i++){
printf("%02x ", s[i]);
}
printf(" ");
for (i=0; i<16; i++){
if (s[i]>=32 && s[i]<=125)printf("%c", s[i]);
else printf(".");
}
s += 16;
printf("\n");
}
// Print out remainder.
if (remainder){
// offset 출력.
printf("0x%08lx ", (long)(s-addr));
// 16 bytes 단위로 출력하고 남은 것 출력.
for (i=0; i<remainder; i++){
printf("%02x ", s[i]);
}
for (i=0; i<(16-remainder); i++){
printf(" ");
}
printf(" ");
for (i=0; i<remainder; i++){
if (s[i]>=32 && s[i]<=125) printf("%c", s[i]);
else printf(".");
}
for (i=0; i<(16-remainder); i++){
printf(" ");
}
printf("\n");
}
return;
} // HexDump.
실행 화면

'Operating System' 카테고리의 다른 글
| [파일시스템] FAT16 파일시스템 (1/3) (0) | 2020.05.26 |
|---|---|
| [파일시스템] 파티션 (1) | 2020.05.26 |
| [임베디드OS개발프로젝트] 5장. UART (0) | 2020.01.20 |
| [임베디드OS개발프로젝트] 4장. 부팅하기 (0) | 2020.01.12 |
| [임베디드OS개발프로젝트] 3장. 일단 시작하기 (0) | 2020.01.11 |